
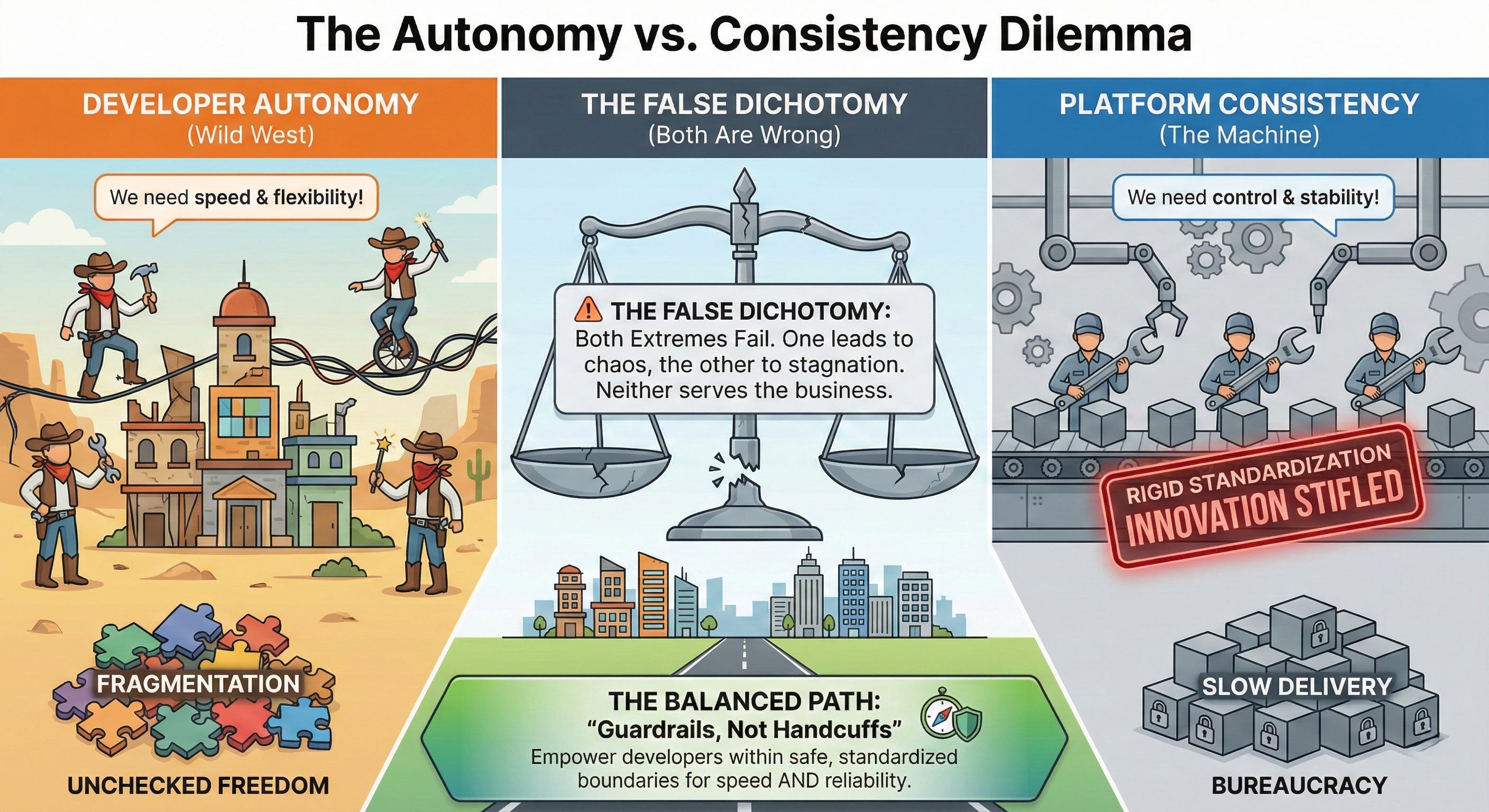
TCP #106: Developers want autonomy. Platform wants consistency. Both are wrong.
Not because either position is bad. Because neither one is a strategy.

You can also read my newsletters from the Substack mobile app and be notified when a new issue is available.

This tension is as old as platform engineering itself.
Developers want to move fast. They want to choose the tools they know. They want to deploy without filing a ticket or waiting for a pipeline they did not build.
Platform teams want predictability. They want one observability stack, one deployment model, and one set of guardrails that applies across every team.
Both are right.
Both, taken to their conclusion, produce organizations that cannot scale.
AUTONOMY IS RIGHT UNTIL IT ISN’T
The case for developer autonomy in platform engineering is real.
Engineers closest to the problem understand the constraints better than anyone else.
A team building a real-time data pipeline knows what latency profile they need. A team managing a compliance-critical workflow knows where the edge cases are.
Giving them the tools and the freedom to solve their problem without platform overhead produces faster decisions and better systems for that specific problem.
Autonomy also drives platform adoption.
Teams that feel constrained by a platform find workarounds. They build shadow infrastructure. They use unapproved tooling. They create exactly the inconsistency the platform was designed to prevent, except now it is invisible to the platform team.
Developer autonomy, when it works, is not chaos. It is trust.
It signals that the platform team respects engineering judgment and is not building for control.
The failure mode is not autonomy itself. It is autonomy without any shared foundation.
Twelve teams. Eight deployment mechanisms. Six observability stacks. No consistent tagging. No shared on-call model. No golden path anyone actually walks.
At that point, developer autonomy has produced a system nobody can operate at scale.
Incidents cross service boundaries that no single engineer understands. Compliance audits require twelve different evidence formats. New engineers spend months learning the local conventions of each team before they can contribute.
CONSISTENCY IS RIGHT UNTIL IT ISN’T
The case for platform consistency is equally real.
When every team deploys through the same pipeline, tags resources consistently, and emits metrics in the same format, the platform team can support them all.
Incidents become diagnosable because the signal looks the same across every service.
Compliance audits become repeatable because the evidence structure does not change between tenants.
Cost attribution becomes automatic because the tagging model is enforced rather than aspirational.
Consistency is what makes a platform team of seven supportable across seventy-five developers.
Without it, every team becomes its own operational burden.
The failure mode is not consistency itself. It is consistency applied to the wrong layer.
When a platform mandates a specific logging library, a specific test framework, a specific database client, it has crossed from enforcing operational standards into controlling engineering decisions that belong to the team.
That is where platform adoption collapses.
Engineers do not fight the pipeline. They route around it. They build locally and push to production via the path with the least friction, which is now outside the platform’s visibility.
The platform team has achieved consistency on paper and lost it in practice.
WHERE BOTH GO WRONG AT THE SAME TIME
The trap is not picking the wrong side.
The trap is treating this as a values conflict between platform control and developer freedom, then oscillating between them based on whoever complained most recently.
Platform teams that get burned by inconsistency clamp down. They add mandatory steps. They restrict tool choices. Developers push back. The platform team softens the requirements. Inconsistency returns.
The cycle repeats.
Neither position is wrong. Both are responding to real failure modes.
The problem is that swinging between them is not a strategy. It is a symptom of not having a clear model for where consistency is non-negotiable and where developer autonomy is not just acceptable but preferable.
HOW TO HOLD THE TENSION
The resolution is not a compromise. It is a boundary.
Define what the platform owns and what the team owns. State it explicitly. Enforce the platform’s layer. Leave the team’s layer genuinely open.
The platform owns: tagging, account structure, network topology, deployment gates, security baselines, compliance controls, and observability standards.
These are non-negotiable because variation here creates systemic risk. One team’s non-standard deployment gate becomes a compliance gap that blocks the entire organization’s certification.
The team owns: language, framework, internal libraries, database choice within approved types, caching strategy, and service architecture.
These decisions belong to the engineers closest to the problem. The platform’s job is not to make these decisions for them. It is to make sure those decisions do not create operational or compliance risk at the system level.
The golden path in platform engineering is not a mandate. It is an offer.
Here is the fastest way to build and ship something that is secure, compliant, and observable. Use it if it fits.
If it does not fit, tell the platform team why, and we will decide together whether the standard needs to change or the exception needs guardrails.
That conversation is what separates a platform developers trust from one they tolerate.
When developers can see exactly where the boundary is, and it is set at the right layer, the autonomy vs. consistency tension stops being a conflict.
It becomes a design.
The platform’s job is not to eliminate developer judgment. It is to make sure that judgment operates within boundaries that the whole organization can rely on.
This week, write a one‑page “platform vs team” RACI:
List: tagging, accounts, network, deploy gates, security, observability
List: language, framework, DB within approved list, caching, service architecture
Circle which ones are fuzzy today. Those fuzzies are where your incidents and platform fights are coming from.
Free tool: Score your AWS platform’s predictability in 5 minutes
I just shipped a new free tool for you: a 6‑page, 18‑question checklist to score how predictable your AWS platform really is across deployments, incidents, onboarding, cost, compliance, and throughput.
It takes 5 minutes and tells you if you’re in Reactive, Stabilizing, or Predictable territory, plus what to fix first.
👉 Grab the free PDF here: https://thecloudplaybook.gumroad.com/l/aws-platform-predictability-check
If you run an AWS platform in production, do this before your next incident review so you’re not guessing which part of the platform will bite you next.
In the paid Cloud Playbook tier, I share the exact “Platform vs Team Contract” template and review checklist I use to draw these boundaries without starting a turf war.
Whenever you’re ready, there are 2 ways I can help you:
Free guides and helpful resources: https://thecloudplaybook.gumroad.com/
Get certified as an AWS AI Practitioner in 2026. Sign up today to elevate your cloud skills. (link)
That’s it for today!
Did you enjoy this newsletter issue?
Share with your friends, colleagues, and your favorite social media platform.
Until next week — Amrut
Get in touch
You can find me on LinkedIn or X.
If you would like to request a topic to read, please feel free to contact me directly via LinkedIn or X.