
TCP #128: ECS, EKS, and Lambda are not the same decision
How team maturity, operational burden, and tenancy reshape the AWS compute choice, and what teams get wrong by treating them as alternatives

Most engineering teams treat the choice of AWS compute as a matter of preference.
Lambda for the team that wants serverless.
ECS for the team that prefers containers.
EKS for the team that wants Kubernetes.
The conversation runs for an hour, the team picks the option that fits how it already works, and the service ships.
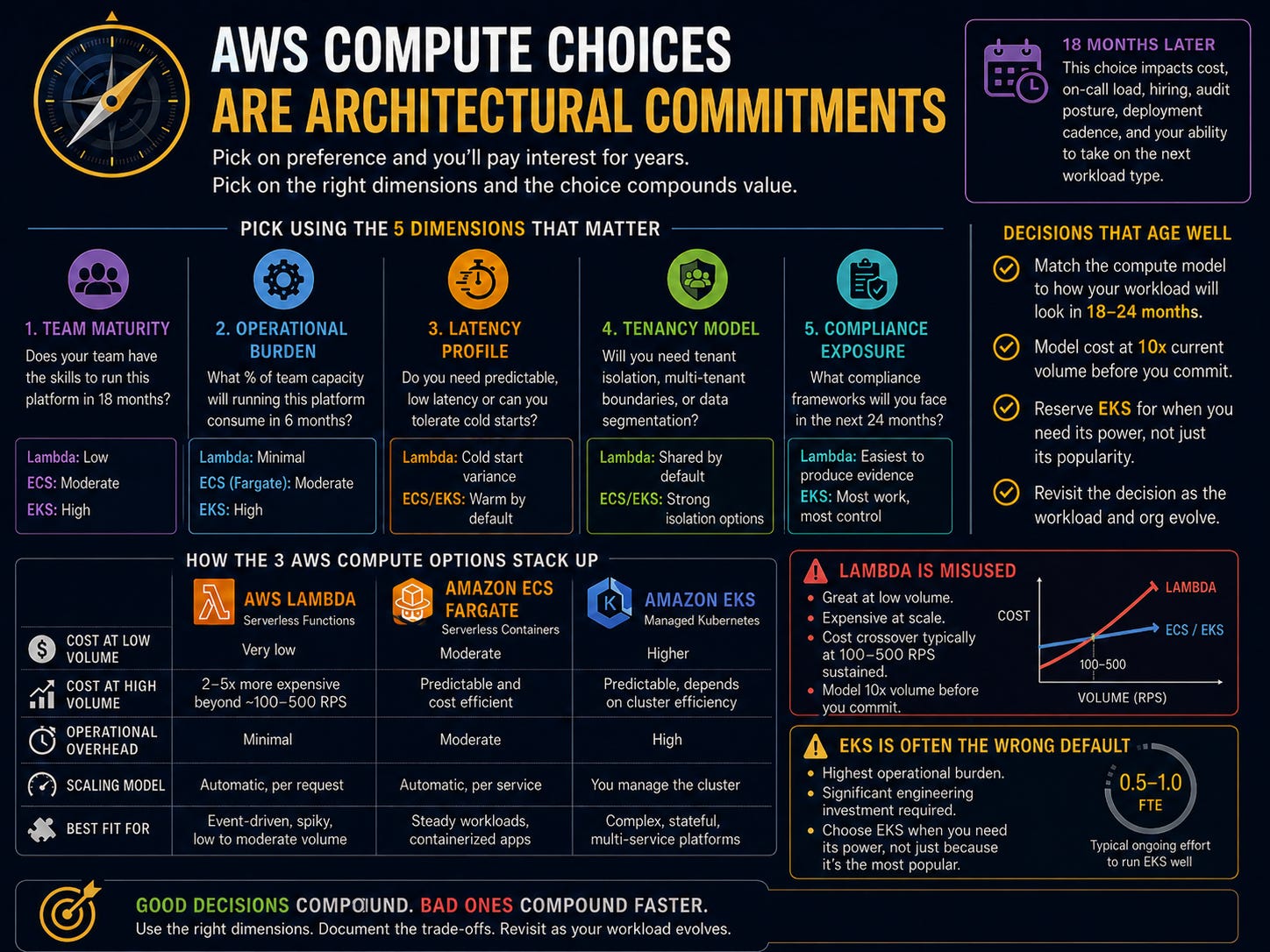
Eighteen months later, the choice is the most consequential architectural commitment the team has made. It governs cost, on-call load, hiring, audit posture, deployment cadence, and the team’s ability to take on the next workload type. It is harder to change than the database choice and almost as hard as changing the account topology.
The teams that get this right do not pick based on preference.
They pick based on five dimensions that determine whether the choice will compound value or compound debt: team maturity, operational burden, latency profile, tenancy model, and compliance exposure.
The teams that get this wrong pick based on what they already know.
Why Familiarity Is the Wrong Decision Criterion
Familiarity is the default tiebreaker, and it is the wrong one.
The argument for familiarity is operational. The team that picks the technology it knows ships faster, debugs faster, and produces fewer incidents in the first six months. This is correct. It is also short-sighted.
The argument against familiarity is structural. Most engineering teams will make compute choices for workloads that grow in volume, expand in tenancy, and acquire new compliance scope. Familiarity at year zero produces operational comfort. By year two, the workload no longer matches the compute model the team chose, and the cost of the mismatch is paid by every team that runs on the same platform.
The teams that pick on familiarity end up with three compute platforms five years later, each one chosen by a different team for a different workload, each one operationally expensive. The platform team inherits the burden of supporting all three.
The Five Dimensions That Should Drive the Choice
Compute selection is a multi-dimensional decision. The five dimensions below yield recommendations that differ from those of the familiarity heuristic.
Team maturity
Lambda is the lowest operational burden of the three. ECS is moderate. EKS is high. The team’s operational maturity does not need to match the platform’s complexity at year zero, but it needs to match within 18 months. A team with no Kubernetes experience that picks EKS will be operating an architecture they cannot debug for two quarters. A team with deep container experience that picks Lambda will hit cold-start, package size, and orchestration limits within a year.
Operational burden
Lambda offloads scaling, patching, and runtime management to AWS. ECS Fargate offloads node management, but the team still owns container lifecycle. EKS carries almost all of the operational burden with the team. The right question is not “which is easier.” The right question is “what fraction of the team’s capacity can be dedicated to running this platform six months from now?” If the answer is 0 percent, then the choice is between Lambda and Fargate. If the answer is 30 percent, EKS is on the table.
Latency profile
Lambda has cold-start variance, which can be addressed but never eliminated. The variance is incompatible with sub-100ms P99 SLOs for low-volume services. ECS and EKS have warm capacity by default. For latency-critical workloads, the cold-start question is not theoretical. It is the deciding factor.
Tenancy model
Lambda is shared-tenant by default, and tenant isolation is operationally awkward. ECS and EKS support tenant isolation through cluster topology, namespace boundaries, and IAM scope. For SaaS workloads that will need per-tenant isolation in the future, the tenancy commitment made today shapes whether that future is achievable.
Compliance exposure
All three services support common compliance frameworks. The differences are in the operational effort required to produce evidence. Lambda’s logging and configuration boundary is the simplest. EKS produces the most evidence but also requires the most work to properly configure it. The compliance frameworks the team will face in the next 24 months should drive this dimension.
Why Lambda Is Misused
Lambda is the most misused compute service in AWS. The misuse is not technical. It is economic.
Lambda is priced per invocation and per millisecond of execution. At low volume, this is dramatically cheaper than running a container fleet. At high volume, it is dramatically more expensive. The cost crossover varies by workload, but for typical request-response services, it sits somewhere between 100 and 500 RPS sustained. Below the crossover, Lambda saves money. Above the crossover, Lambda costs 2 to 5 times as much as an equivalent ECS or EKS deployment.
Most teams choose Lambda based on their current volume. They forecast linearly. They do not model the workload at the volume it will reach in 18 months. By the time the cost trajectory becomes visible in the AWS bill, the architecture is load-bearing, and the migration cost is high.
The Lambda choice is not wrong. The Lambda choice without a written cost trajectory at 10x current volume is wrong.
Why EKS Is Often the Wrong Default
EKS has become the default container choice for engineering teams that want maximum flexibility. The argument is reasonable: Kubernetes is the broadest ecosystem, the most portable, the most powerful.
The argument also misses two structural realities.
First, the operational burden is not optional. EKS requires the team to operate cluster networking, ingress, pod scheduling, node lifecycle, secrets management, observability instrumentation, and security boundaries. AWS manages the control plane. The team manages everything else. The team that picks EKS is committing to roughly 0.5 to 1.0 FTE of platform work that does not directly produce product value.
Second, the flexibility is rarely used. Most workloads that pick EKS do not use the features that justify the operational burden. They run a deployment, a service, and an ingress. ECS Fargate would run the same workload with a fraction of the operational overhead and no portability cost; the team would actually exercise.
EKS is the right choice when the team has a portfolio of workloads that justify the platform investment, a strong commitment to Kubernetes patterns across services, or a specific feature, such as custom schedulers, that ECS does not support. It is the wrong choice for the team to pick it because the rest of the industry is using it.
Why ECS Is Underestimated
ECS does not have the brand prestige of Kubernetes. It lacks the elegance of Lambda. It has the property that matters more than either: it requires the least operational burden for the broadest range of workloads.
ECS Fargate runs containers without node management. It integrates with the rest of AWS through native primitives rather than abstractions. It produces logs, metrics, and traces through standard AWS instrumentation. It has been generally available longer than EKS and is operationally mature.
For most SaaS workloads, ECS Fargate is the correct default. It supports latency profiles, tenancy models, and compliance frameworks. It does not require the team to operate a Kubernetes cluster. It does not lock the team into Lambda’s pricing trajectory.
The teams that build on ECS as the default and reach for Lambda or EKS only when the workload demands it produce platforms with lower operational burden and better cost trajectories than the teams that pick on preference.
Four Questions That Drive the Right Choice
Before the team picks a compute service, four questions should be answered in writing. The questions take an hour. They prevent the wrong choice from compounding for years.
What is the team’s operational capacity for this workload at month 12
Not month zero. The team has Slack at month zero because the workload is new. By month 12, the workload is one of several. If the team will not have 30 percent of an FTE available to run a Kubernetes cluster, EKS is not on the table.
At 10x current volume, what does this cost?
Lambda’s cost trajectory hides at low volume and surfaces at high volume. Modeling 10x growth at decision time exposes the cost cliff. If the model shows Lambda becoming uneconomic at the forecast volume, the choice should be ECS or EKS.
What latency SLO does the workload need?
Sub-100ms P99 with low volume is incompatible with Lambda cold-start variance unless provisioned concurrency is paid for. For workloads with strict latency requirements and low base load, ECS or EKS are the only viable choices.
What tenancy and compliance requirements will the workload need in 24 months?
If the future includes per-tenant isolation for regulated customers, the compute choice today should not foreclose that future. Lambda’s tenancy model is the most awkward to evolve. ECS and EKS both support evolution but require different paths.
The team that answers these four questions makes a different choice than the team that picks based on preference. The choice is not always the same. It is always more defensible.
What Changes When Computing Is a Risk Decision
Engineering organizations that treat compute selection as a risk decision rather than a preference produce different outcomes.
The platform team consolidates on fewer compute models, reducing operational burden and improving the team’s ability to ship golden paths.
The cost forecast is accurate because each workload was modeled during growth, before the architecture shipped.
The compliance posture is consistent because the compute choice was filtered through the compliance scope at decision time.
The team’s hiring profile becomes coherent because computed commitments determine which kinds of engineers the team needs to recruit, develop, and retain.
The choice of a computer does not become invisible. It becomes the single most important architectural commitment the team makes. The teams that treat it that way ship platforms that compound. The teams that treat it as a preference ship platforms that fragment.
On Wednesday, paid subscribers get the complete ECS vs EKS vs Lambda decision framework: a scoring matrix that evaluates a candidate workload across team maturity, operational complexity, compliance impact, cost trajectory, and ownership.
The framework includes weighted scoring, the threshold rules that drive the recommendation, and three worked examples covering an internal service, a customer-facing API, and a regulated multi-tenant workload.
Upgrade If You Need Implementation, Not Just Ideas
If you’re using these emails to guide real decisions on your platform, you’ll get more leverage from the paid version of The Cloud Playbook.
The free newsletter gives you patterns and language.
The paid newsletter turns those patterns into implementation kits you can ship inside a quarter:
Concrete rollout plans (90‑day roadmaps for each pattern)
Templates and checklists (policies, runbooks, tagging schemes, review checklists)
Real examples from high‑stakes AWS environments (what we actually shipped and why)
If the paid side doesn’t save you more than the subscription in one incident, audit cycle, or bad migration you avoid, you should cancel and keep the playbooks.
That’s it for today!
Did you enjoy this newsletter issue?
Share with your friends, colleagues, and your favorite social media platform.
Until next week — Amrut
Get in touch
You can find me on LinkedIn or X.
If you would like to request a reading topic, please feel free to contact me directly via LinkedIn or X.