
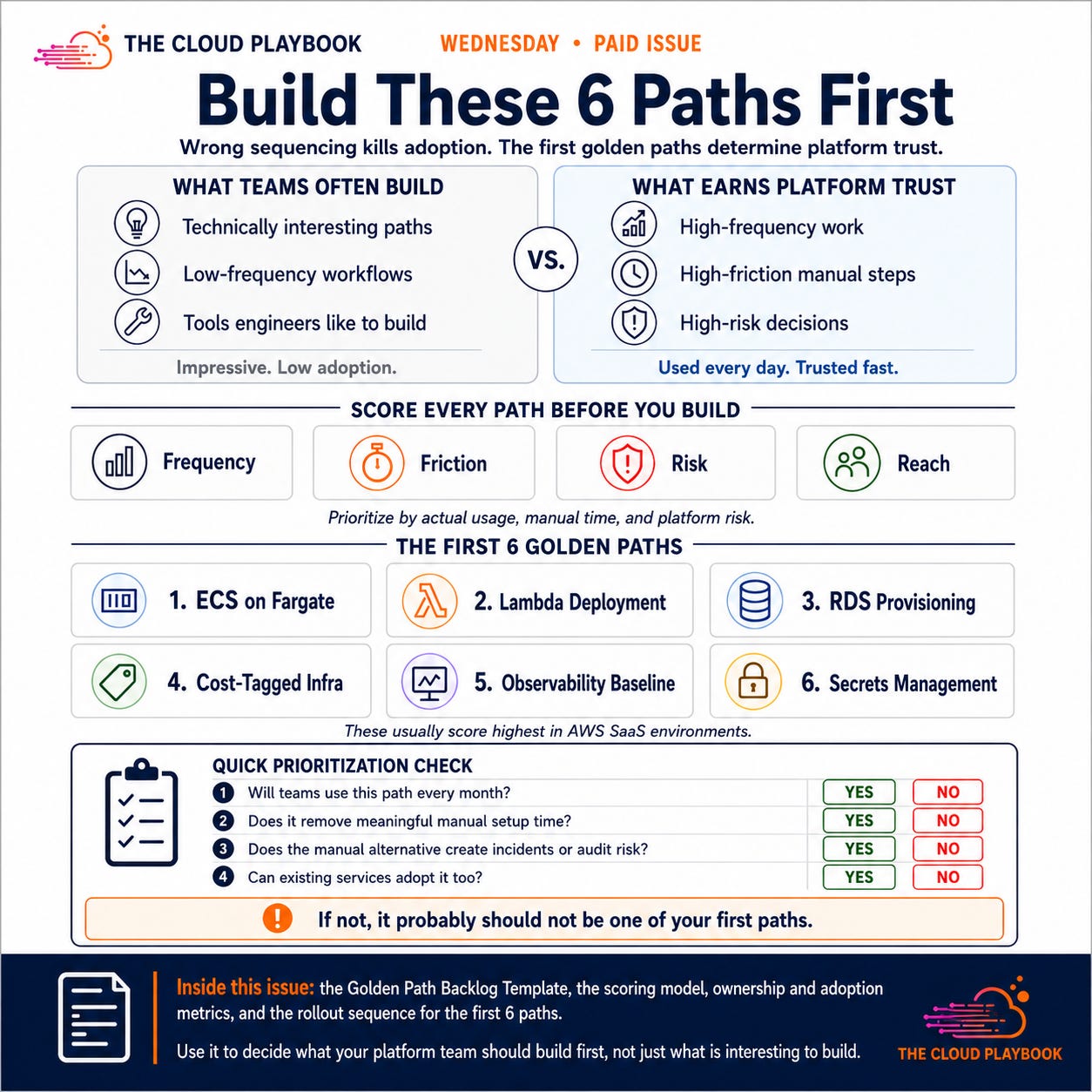
TCP# 124: The 6 golden paths worth building first, and how to sequence them.
Scored by frequency, friction, risk, and reach. With backlog template and adoption metrics.

Platform teams rarely have a golden path shortage. They have a sequencing problem.
The backlog of potential paths is long: containerized deployments, serverless functions, database provisioning, secrets management, observability setup, CI/CD templates. Every senior engineer has a candidate. Every app team has a complaint about the current manual process.
The question is not what to build. It is what to build first.
Wrong sequencing produces low adoption. A golden path for Kubernetes service mesh configuration is technically impressive and practically irrelevant if most teams are still deploying Lambda functions manually. App teams ignore paths that don’t match their daily work. The platform team loses credibility before the program gets traction.
Why the Sequence of Golden Paths Determines Platform Trust
The first three paths a platform team ships set the tone for everything that follows.
If the first paths are fast, correct, and clearly easier than the alternative, app teams adopt them. They stop routing around the platform. They start asking for the next path instead of building their own. The platform team earns the right to set standards for more complex decisions.
If the first paths are slow to produce, hard to use, or misaligned with what teams actually need in their daily work, adoption fails. Platform engineering becomes the team that built tools nobody uses. Credibility takes quarters to rebuild.
The first six paths are not a starting point. They are the foundation of platform trust.
The Failure Mode: Building for Interest Instead of Impact
Most platform teams prioritize golden paths based on what is technically interesting to build, not on what creates the most daily impact for app teams.
They build a Kubernetes deployment path because the platform engineers are skilled in Kubernetes. They build an advanced multi-region failover path because it is architecturally sophisticated. They build a developer portal integration because it makes a good conference talk.
Meanwhile, every app team is manually configuring Lambda functions with inconsistent IAM roles, provisioning RDS instances without encryption enforcement, and setting up CloudWatch alarms from scratch for every new service. These are the gaps producing incidents, cost anomalies, and audit findings right now.
A golden path program that prioritizes interesting work over daily friction earns goodwill from platform engineers and indifference from app teams.
A Scoring Model for Golden Path Prioritization
Score each candidate path across four dimensions before committing the build investment.
Frequency. How many engineers would use this path in a given month? A path used daily by every team outranks one used once per quarter by a single team. Count the actual provisioning events, not the theoretical ones.
Friction. How much time does the current manual approach cost? A path that eliminates 90 minutes of manual configuration per deployment creates more measurable value than a path that eliminates 10 minutes.
Risk. What goes wrong when teams build without this path? Score on two sub-dimensions: incident risk (how often has the manual approach produced a production failure?) and audit risk (how often has the manual approach produced a compliance gap?).
Reach. How many existing services would benefit from retroactive adoption? A path that applies to 40 current services without re-provisioning creates value beyond new deployments.
The six paths below score highest across these four dimensions in most AWS SaaS environments.
The Six Paths, Scored and Sequenced
Path 1: Containerized Service Deployment (ECS on Fargate)
The highest-frequency deployment pattern for most SaaS platform teams. Manual deployment requires engineers to configure the task definition, ECS service, target group, log group, IAM execution role, and cost allocation tags independently and consistently.
Owner: Platform Engineering, compute chapter
What the module covers: Task definition template, ECS service configuration, ALB target group, CloudWatch log group with standard retention, IAM execution role with least-privilege policy, required cost tags
Adoption metric: Percentage of new ECS services deployed via the module in the trailing 30 days
Rollout sequence: Release to one app team as a pilot, collect feedback on friction points, iterate, then open to all teams
Path 2: Serverless Function Deployment (Lambda)
Lambda is the second-highest-frequency deployment pattern and the one most likely to have inconsistent IAM scopes and missing observability in existing deployments.
Owner: Platform Engineering, serverless chapter
What the module covers: Function configuration with runtime defaults, IAM execution role scoped to required permissions, CloudWatch log group with retention policy, error rate alarm with defined threshold, required cost and service tags
Adoption metric: Percentage of new Lambda functions with IAM roles sourced from the module’s policy template
Rollout sequence: Pilot with the team that has the most Lambda functions in production, prioritize retroactive adoption to close existing IAM and observability gaps
Path 3: Managed Relational Database Provisioning (RDS)
Database provisioning has the highest incident and audit risk among self-service infrastructure decisions. Encryption at rest, backup retention, deletion protection, subnet group placement, and parameter group selection are regularly misconfigured by teams building in the AWS console or from memory.
Owner: Platform Engineering, data chapter
What the module covers: Instance class guardrails by environment tier, encryption at rest enforced, automated backup enabled with defined retention period, deletion protection enabled in production, subnet group assignment to private subnets, parameter group set to approved baseline, required tags
Adoption metric: Percentage of RDS instances in production accounts that were provisioned via the module
Rollout sequence: Release to production after extensive testing in staging, prioritize retroactive compliance for existing instances
Path 4: Cost-Tagged Infrastructure Module
Every resource type in your environment should apply a consistent set of cost allocation tags. The alternative is a quarterly archaeology project to attribute spend. This path is not a deployment module for a specific resource. It is a tagging standard embedded in every other module.
Owner: Platform Engineering, FinOps chapter
What the module covers: Required tag definitions (team, product, environment, cost-center, service-owner), tag validation logic, tag policy enforcement via AWS Config or Terraform plan validation, tag propagation to child resources
Adoption metric: Percentage of resources in production accounts that carry all required cost allocation tags
Rollout sequence: Release as a dependency of Paths 1, 2, and 3 — embedded, not optional
Path 5: Observability Baseline for New Services
Every new service needs CloudWatch metrics, structured log groups, distributed tracing, and at least two alarms: one on error rate and one on latency. Teams building without this path produce services that are invisible until they fail.
Owner: Platform Engineering, observability chapter
What the module covers: CloudWatch metric namespace for the service, log group with structured format and retention policy, X-Ray tracing enabled, error rate alarm, p99 latency alarm, dashboard template for the service’s health view
Adoption metric: Percentage of services in production with all five observability components present
Rollout sequence: Release alongside Path 1 and Path 2 so new service deployments include observability by default
Path 6: Secrets Management Pattern (AWS Secrets Manager)
Hardcoded credentials and environment variables containing secrets are among the most common audit findings on cloud platforms. This path eliminates the decision: secrets go in Secrets Manager, with rotation enabled, and the application accesses them via a scoped IAM policy.
Owner: Platform Engineering, security chapter
What the module covers: Secrets Manager secret provisioning with rotation enabled, rotation Lambda for supported secret types, IAM policy granting read access scoped to the specific secret, resource policy blocking cross-account access by default
Adoption metric: Percentage of application secrets accessed via Secrets Manager vs. environment variables or parameter store without rotation
Rollout sequence: Pilot with one team migrating hardcoded credentials, document the migration steps, then open as the default secret provisioning path
Artifact in This Issue
The artifact is the Golden Path Backlog Template: a structured planning table for sequencing your golden path program.
Each row in the template contains:
Path name and type (deployment, provisioning, configuration, observability)
Problem solved: the specific manual process this path replaces
Frequency score: monthly provisioning events across the engineering org
Friction score: estimated hours of manual work eliminated per use
Risk score: incident and audit risk rating from the manual approach
Reach score: number of existing services that can retroactively adopt the path
Total priority score and recommended sequencing position
Owner team and implementation scope summary
Adoption metric definition
Rollout sequence steps (pilot, feedback, iterate, release)
Use this template in your next platform engineering planning session to build your own prioritized golden path backlog. Score each candidate path against your actual provisioning data, not estimates. The team that deploys 20 Lambda functions per month has a higher friction score for Path 2 than the team that deploys two.
What to Measure and When to Review
Adoption rate per path. Percentage of new deployments using the golden path module in the trailing 30 days. Track per path, not as a single aggregate. Paths with adoption below 60 percent within 90 days of release need a friction audit.
Drift rate. Percentage of existing services that were compliant with the path standard at release but have since drifted. High drift indicates the path lacks enforcement mechanisms. It is documentation, not a system.
Time saved per deployment. Estimate the manual configuration time eliminated by each path use. Accumulate monthly. This number converts golden path investment into engineering hours returned to product work, which is the right currency for the conversation with the VP of Engineering.
Review path adoption metrics monthly in the platform team’s operating review. Review the prioritized backlog quarterly to add candidates, retire unused paths, and promote complex paths to simpler defaults as adoption matures.
What the First Six Paths Actually Build
The six paths above are not primarily about technical consistency, though they produce it.
They are about demonstrating that the platform team solves real problems fast, makes the right choice the easy choice, and delivers value that app teams can measure in time and incidents.
When the first six paths land well, app teams stop routing around the platform. They start requesting paths 7 through 12. The platform team stops defending its investment and starts negotiating for the capacity to expand it.
The path program that scales is not the one with the most sophisticated architecture. It is the one that earned trust early by solving the problems teams had every day.
Use the backlog template as your agenda for next quarter’s planning. Score your top ten candidate paths before the session so the team is debating real data, not intuition. Forward this issue to the senior engineers and EMs who own the highest-friction provisioning workflows on their teams. They are the ones who know where the manual time is going.
That’s it for today!
Did you enjoy this newsletter issue?
Share with your friends, colleagues, and your favorite social media platform.
Until next week — Amrut
Get in touch
You can find me on LinkedIn or X.
If you would like to request a topic to read, please feel free to contact me directly via LinkedIn or X.