
TCP#99: Platform engineering is load reduction, not tooling
Platform success is not adoption charts.

You can also read my newsletters from the Substack mobile app and be notified when a new issue is available.

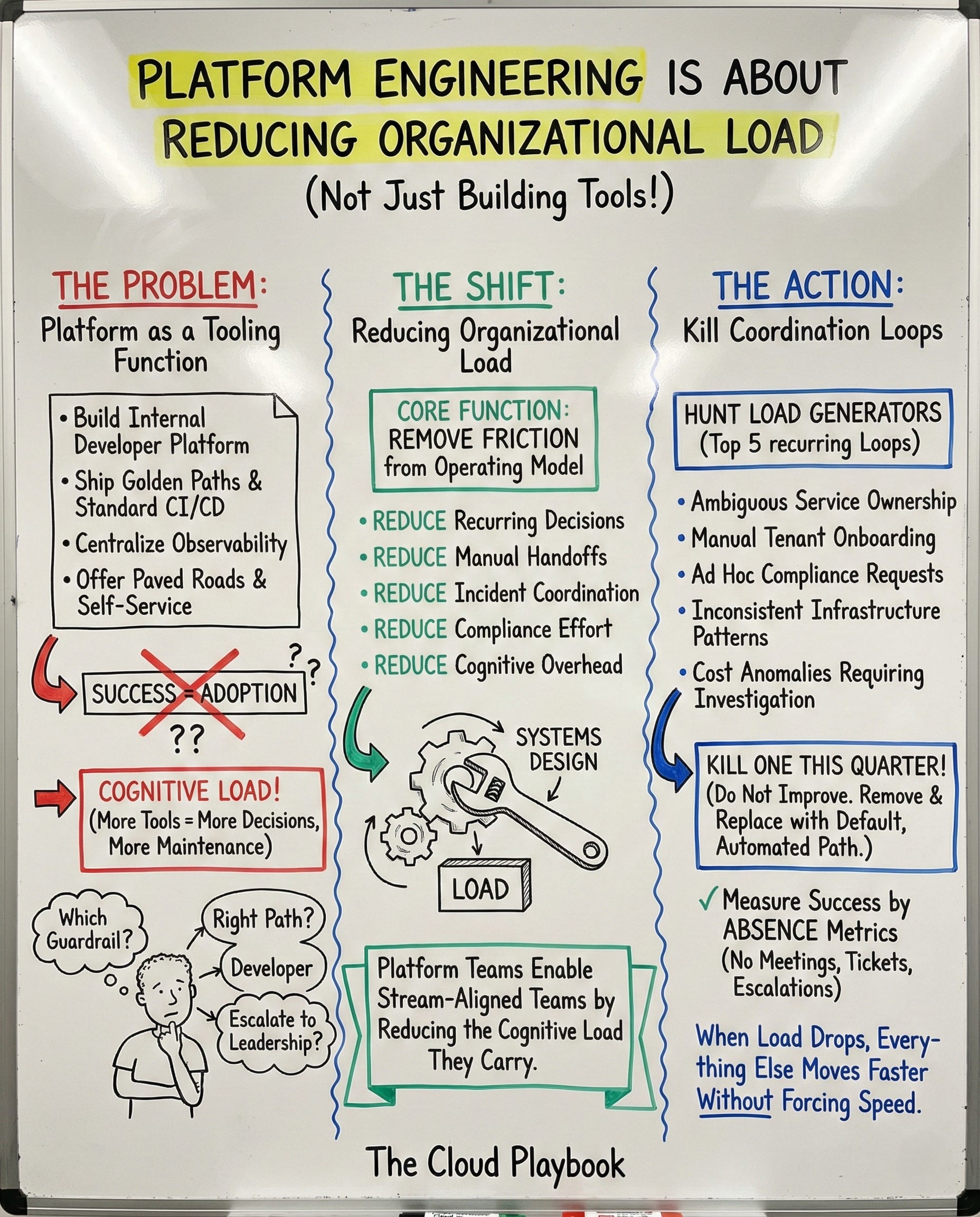
Platform engineering is usually framed as a tooling function.
Build an internal developer platform. Ship golden paths. Standardize CI/CD. Centralize observability. Offer paved roads and self-service infrastructure.
Success becomes adoption.
How many teams are using the platform? How quickly new services spin up? How many templates get reused?
Under this framing, platform teams are measured in the same way as internal product teams.
Ship features. Improve developer experience. Reduce friction. Increase autonomy.
This framing is incomplete. It focuses on what platform teams produce rather than what they remove.
Tools can increase cognitive load
When platform engineering is treated as a tooling discipline, organizations end up adding complexity rather than reducing it.
Every new tool adds choices. Every template adds a maintenance surface. Every internal product requires documentation, support, and governance. Instead of simplifying the system, the platform becomes another layer teams must navigate.
This is what cognitive load looks like in practice.
Developers must remember the “right” path across environments. Teams must learn which guardrails are real and which are optional.
Leaders must arbitrate escalation paths when incidents span boundaries. The organization pays coordination overhead because the system is not explicit about defaults.
Industry language often describes the platform’s job as reducing cognitive load. That is a useful entry point, and it is widely stated in platform engineering and IDP definitions.
But the deeper failure mode is not just cognitive load for developers.
It is organizational load across the entire operating model. Decision load. Coordination load. Ownership load.
Engineers spend time choosing among paths rather than following defaults.
Leaders spend time resolving ownership conflicts instead of delivering outcomes. Incidents escalate across teams because boundaries are unclear.
Compliance evidence is gathered manually because systems were not designed to produce it automatically.
Most platform initiatives fail not because the tools are bad. They fail because they increase the organization's total operational burden.
A platform that adds options without removing decisions is not a platform. It is an additional system to manage.
Platform engineering reduces organizational load
Platform engineering is not about building tools. It is about reducing organizational load.
The core function of a platform team is to remove friction from the company's operating model.
Reduce the number of decisions teams must make repeatedly. Reduce the number of handoffs required to ensure safe shipping. Reduce the coordination required during incidents. Reduce the effort required to prove compliance. Reduce the cognitive overhead of deploying and operating software.
This is a systems design problem. Not a tooling problem.
Tools are one mechanism. They are not the objective.
Platform teams exist to enable stream-aligned teams by reducing the cognitive load they must carry to deliver value.
If your platform work does not reduce recurring decisions and coordination, it is not reducing load. It is relocating it.
What changes when you see it this way
Your roadmap stops being feature lists.
Priorities shift immediately.
Instead of asking what tools to build next, you ask which recurring decisions are consuming the most organizational energy.
Instead of measuring feature adoption, you measure the reduction in manual coordination.
Instead of optimizing for developer happiness alone, you optimize for clarity of ownership and default behavior.
This is where “platform as a product” becomes useful. Not because you want to behave like an internal SaaS vendor.
Because you need discipline to eliminate friction end-to-end. Research, understand, simplify, ship defaults, and remove escape hatches that recreate the problem.
You start hunting load generators.
You start identifying sources of load across the system.
Ambiguous service ownership during incidents.
Manual tenant onboarding that requires cross-team coordination.
Compliance evidence gathered through ad hoc requests.
Inconsistent infrastructure patterns that increase debugging time.
Cost anomalies that require investigation across multiple teams.
Each of these is a load generator. Each consumes time and attention across engineering, security, and leadership.
The platform response is not to build more dashboards or add more documentation. The response is to eliminate the underlying coordination requirement.
Ownership becomes encoded into infrastructure and runbooks.
Onboarding becomes automated and standardized.
Evidence is generated by default through logging and configuration baselines.
Cost controls are enforced through guardrails rather than after-the-fact reporting.
Organizational load drops because the system becomes explicit.
Your success metrics become absence metrics.
This also changes how you evaluate platform investments.
A new service template is valuable only if it removes repeated decisions.
A new observability layer is justified only if it reduces incident ambiguity and reduces escalation time.
A compliance automation initiative matters only if it eliminates manual evidence collection.
A cost governance mechanism succeeds only if it reduces executive uncertainty about spend.
If a platform initiative does not reduce organizational load, it is not platform work. It is additional complexity.
Kill one coordination loop this quarter
Map the top five recurring coordination loops in your organization.
Where do teams wait on each other to ship?
Where do incidents stall because ownership is unclear?
Where does compliance require manual effort?
Where do cost reviews require investigation instead of explanation?
Where do new environments require meetings instead of automation?
Treat each loop as a design flaw, not an operational inconvenience.
Assign your platform team to eliminate one of these loops completely within the next quarter.
Do not improve it. Remove it. Replace it with a default, automated, or enforced path that requires no coordination.
Measure success by the absence of meetings, tickets, and escalations that used to exist. If the loop is still there, the load is still there.
When those disappear, organizational load drops. When organizational load drops, everything else moves faster without forcing speed.
Whenever you’re ready, there are 2 ways I can help you:
Free guides and helpful resources: https://thecloudplaybook.gumroad.com/
Get certified as an AWS AI Practitioner in 2026. Sign up today to elevate your cloud skills. (link)
That’s it for today!
Did you enjoy this newsletter issue?
Share with your friends, colleagues, and your favorite social media platform.
Until next week — Amrut
Get in touch
You can find me on LinkedIn or X.
If you would like to request a topic to read, please feel free to contact me directly via LinkedIn or X.