
TCP# 110: The question that quietly kills your incident response
Platform teams don’t fail because of bad tools. They fail because, at 2 am, nobody can answer one question: who owns this service?

You can also read my newsletters from the Substack mobile app and be notified when a new issue is available.

Platform teams don’t fail because of bad tools.
They fail because nobody can answer one question: who owns this?
Not “who built it.” Not “who is on-call for it this week.”
Who is accountable for its behavior, its health, and its evolution over time?
That question sounds simple. In most organizations, it has no clean answer.
THE SIGNAL MOST LEADERS MISS UNTIL IT’S TOO LATE
The pattern shows up the same way every time.
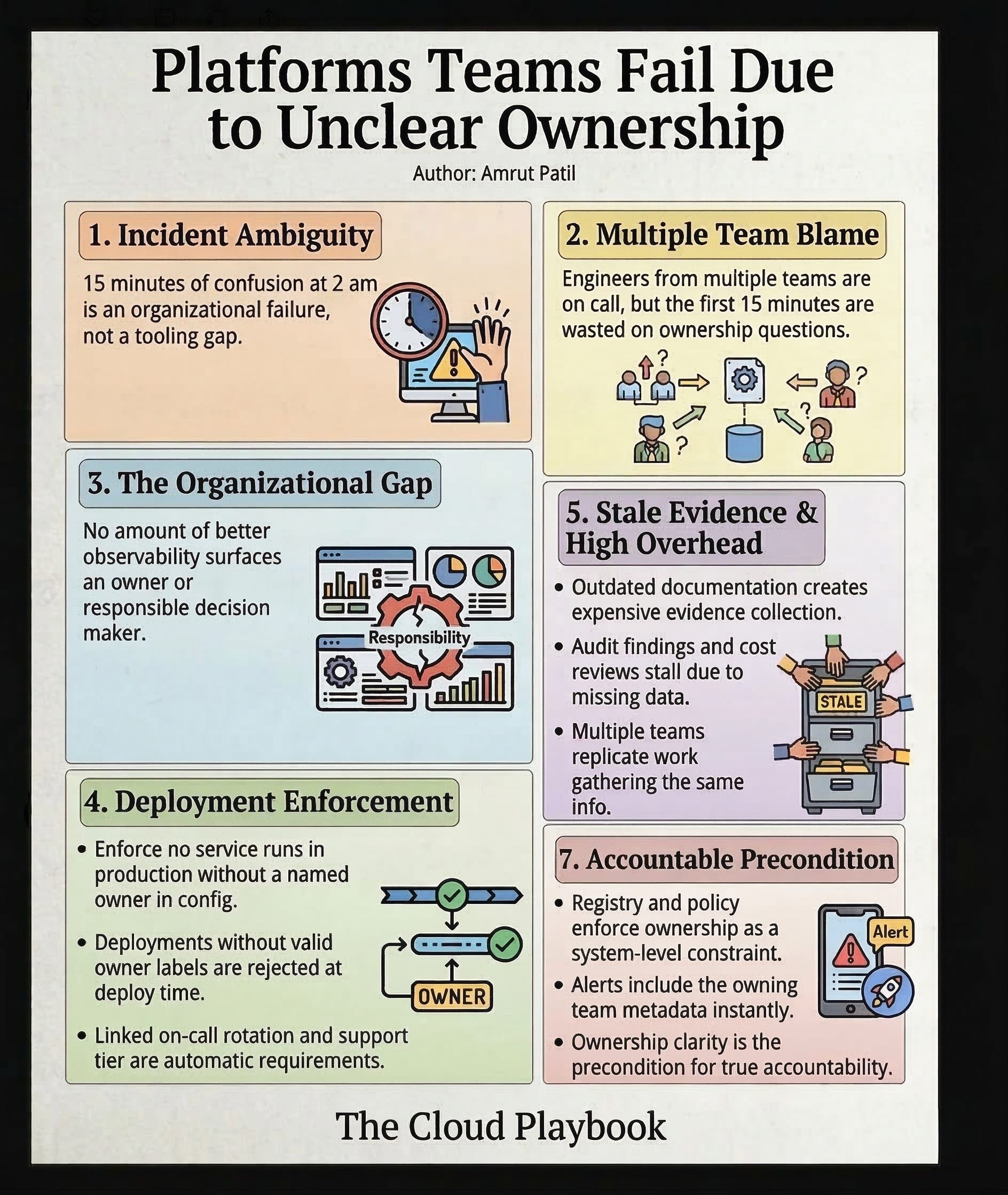
An incident occurred at 2 am. The alert lands in a shared channel. Engineers from three teams join the call. The first fifteen minutes are spent not on the fix, but on the question: whose service is this?
Nobody is lying. Nobody is avoiding the work. The system was just never designed to answer that question clearly.
This is not a tooling gap. No amount of better observability surfaces an owner. No dashboard tells you who is responsible for making a decision. That is an organizational design problem.
The cost is not just the 15 minutes of confusion at 2 am.
The cost compounds: a slower mean time to resolution, higher engineer burnout, recurring incidents because no one has a clear mandate to fix the root cause, and audit findings where evidence collection stalls because nobody owns the system that should automatically produce it.
WHAT UNCLEAR OWNERSHIP ACTUALLY LOOKS LIKE IN PRODUCTION
It does not look like chaos. It looks like reasonable ambiguity.
A service was built by one team, migrated to another, and is now consumed by six. The original team documented it two years ago. The documentation is stale. The consuming teams have added workarounds. No one has updated the service catalog entry because nobody feels like the owner.
During normal operations, this is invisible. The service runs. Nobody asks questions.
During an incident, a compliance audit, or a cost-optimization review, ambiguity becomes costly. Three teams each spend four hours gathering evidence for the same control because none of them is sure who should do it. You pay for that coordination overhead every single time.
The research backs this up. Organizations with explicit ownership models, where every service has a named team, and that assignment is enforced in the deployment pipeline, resolve incidents measurably faster. The ownership metadata is not just a cultural artifact. It is an operational infrastructure.
THE OPERATING PRINCIPLE AT WORK
Ownership is not a feeling. It is a system-level declaration that must be maintained like code.
The fix is not a new tool. It is a new invariant: no service runs in production without a named owner encoded in its configuration, linked to an on-call rotation, and tied to a support tier. That invariant is enforced at deploy time, not suggested in a wiki.
Here is what that looks like concretely.
Every resource in your service catalog carries three fields: owning team, support tier, and deprecation status. Deployments that do not carry valid owner labels are rejected at the infrastructure layer, not flagged afterward. The ownership registry is queried automatically at incident time, so the first alert includes the owning team, not just the service name.
This is not complex to build. It is a webhook, a registry, and a policy. Most teams have the technical capability in a few sprints.
What they lack is the mandate. Ownership enforcement feels bureaucratic until the first incident, where it saves 45 minutes of confusion. After that, engineers stop objecting to it.
The deeper shift is cultural. When ownership is enforced at the infrastructure layer, it stops being a conversation and starts being a constraint. Constraints are honest. They tell you exactly what the system expects of you. That honesty reduces the cognitive overhead that ambiguous shared ownership creates for everyone.
RUN THIS CHECK
What to do this week:
Pull your current service catalog. Count the services with no owner or an owner field pointing to a team that no longer exists. If that number is above 10%, you have a structural problem, not a documentation problem.
Pick one critical service with ambiguous ownership. Assign it to a named team, add the assignment to the deployment configuration, and run a tabletop incident drill where that team is the first call. Track resolution time.
Write down the three services that caused the most escalation overhead in the last quarter. In each case, determine whether the escalation was driven by unclear ownership. It almost always is.
Teams that enforce ownership at the infrastructure layer cut incident mean-time-to-resolution by removing the ownership-discovery step entirely. That step costs more time than most engineering leaders realize, because it rarely appears in post-incident reviews as a distinct line item.
Every time I’ve seen a platform team struggle with recurring incidents in the same service area, the root cause has been the same: the team on-call did not feel accountable because they did not feel like the owner. Ownership clarity is not a nice-to-have. It is the precondition for accountability.
Free tool: Score your AWS platform’s predictability in 5 minutes
If this hit close to home, you probably have other places where ownership and accountability are fuzzy but invisible until something breaks.
To make this practical, I put together a free AWS Platform Predictability Starter Kit for readers:
5‑minute predictability checklist
“Where are we bleeding?” team scorecard
Platform risk radar with 12 early‑warning signals
10 executive questions with weak vs strong answers + debrief worksheet
Most leaders run through these in a week of normal meetings and come away with a clear “top 3” to fix next.
👉 Grab the free PDF here: https://thecloudplaybook.gumroad.com/l/aws-platform-predictability-check
If you run an AWS platform in production, do this before your next incident review so you’re not guessing which part of the platform will bite you next.
In the paid Cloud Playbook tier, I share the exact “Platform vs Team Contract” template and review checklist I use to draw these boundaries without starting a turf war.
Whenever you’re ready, there are 2 ways I can help you:
Free guides and helpful resources: https://thecloudplaybook.gumroad.com/
Get certified as an AWS AI Practitioner in 2026. Sign up today to elevate your cloud skills. (link)
That’s it for today!
Did you enjoy this newsletter issue?
Share with your friends, colleagues, and your favorite social media platform.
Until next week — Amrut
Get in touch
You can find me on LinkedIn or X.
If you would like to request a topic to read, please feel free to contact me directly via LinkedIn or X.