
TCP #108: Who owns this service? (If you need Slack to answer, you have a problem)
Turning ownership from a stale spreadsheet into an enforced AWS constraint wired to tags, on-call, and cost.

You can also read my newsletters from the Substack mobile app and be notified when a new issue is available.

Average teams document ownership. Great teams enforce it.
Most engineering teams have a spreadsheet, a Confluence page, or a service catalog entry that says who owns what. That document gets created during a planning cycle, reviewed once, and then ignored.
Nobody updates it when engineers leave, when services get refactored, or when a new team inherits an old codebase.
The document exists. Ownership does not.
This gap is not a knowledge problem. It is a mechanism problem.
In the paid version of this issue, I include the exact AWS policies, Config rules, and Terraform patterns I use to enforce ownership in regulated environments. This free version explains the pattern so you can decide if it’s worth wiring into your platform.
Until you treat it that way, your incidents will keep revealing owners who did not know they were owners, your audits will surface gaps nobody saw coming, and your cost anomalies will have no clear path to resolution.
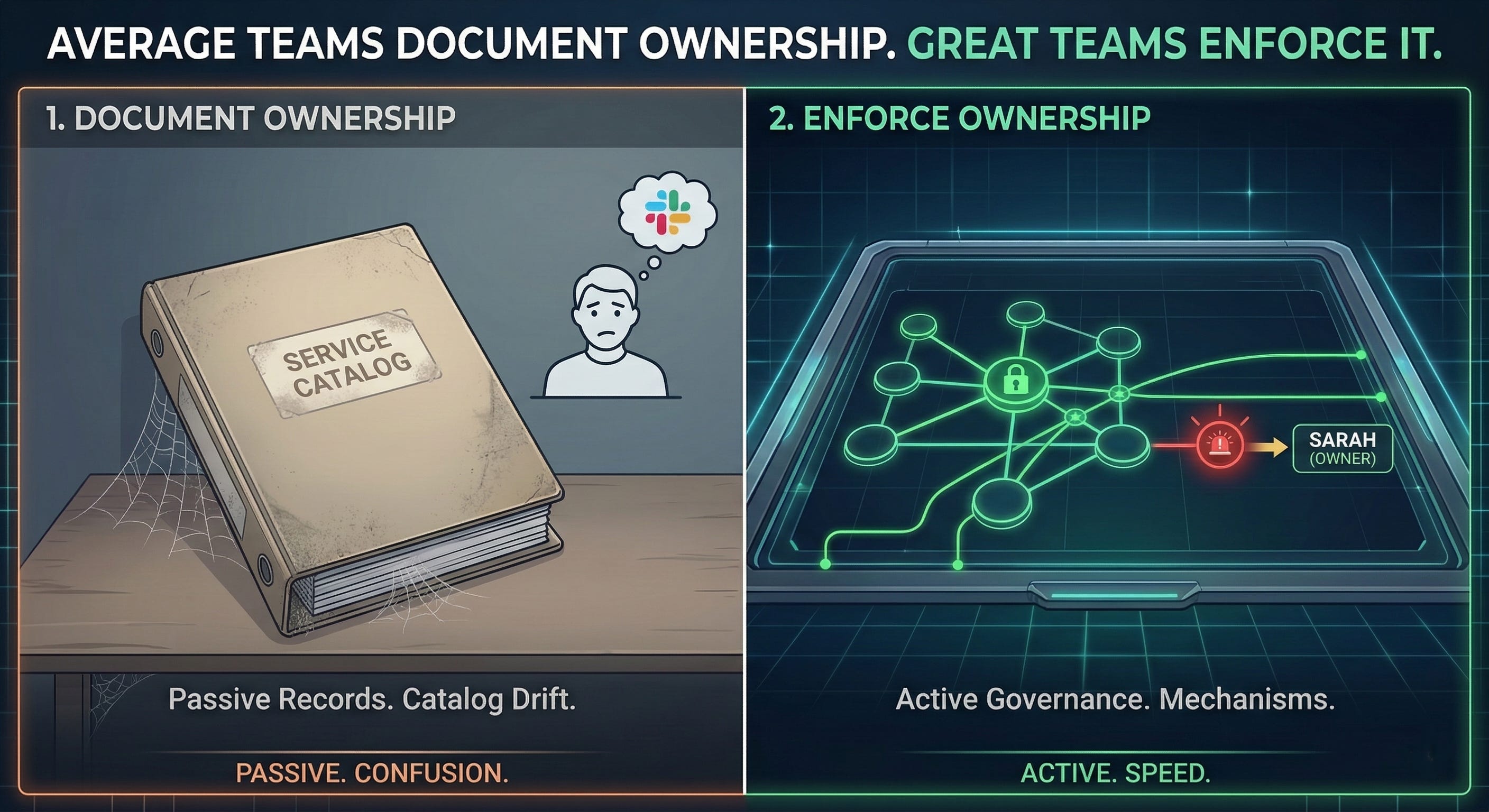
THE CATALOG THAT DRIFTS WHILE YOUR ORG MOVES
Most teams treat ownership as a one-time labeling exercise.
They build a service catalog. They assign owners. They add a field in Backstage or a column in a spreadsheet. A few quarters later, engineers rotate, services split, and the catalog drifts from reality.
The result is a document that looks complete but carries no accountability.
When an incident fires at 2 am, the on-call engineer finds an owner who left eight months ago and starts pinging Slack channels.
The incident resolution time climbs. Post-mortems list “unclear ownership” as a contributing factor. Nobody changes the underlying system.
The same pattern appears in compliance reviews. The team points to documentation. The documentation points to a person who no longer holds that role. The audit finding stems from the fact that the document said one thing, while the organization reflected another.
Documentation without enforcement is not governance. It is the appearance of governance.
OWNERSHIP WIRED TO FUNCTION, NOT IDENTITY
High-performing teams make ownership structural, not declarative.
They do not ask teams to record who owns a service. They build systems that make it impossible to provision a resource without declaring ownership.
They tie that declaration to on-call rotation, cost attribution, and access controls. When ownership changes, the system reflects it within one sprint, or the pipeline breaks.
The mechanism starts at provisioning. AWS Service Control Policies and Tag Policies in AWS Organizations prevent resource creation when mandatory ownership tags are absent.
For paid subscribers, I break down the specific tag keys, example SCPs, and the safe rollout sequence I’ve used so you don’t brick existing pipelines.
The tags include service name, team alias, on-call contact, environment, and cost center. A resource without those tags cannot be deployed. The enforcement is not a reminder. It is a gate.
The owner field points to a team alias or rotation, not a person’s name. When an engineer leaves, the alias stays active. The team updates the rotation. The on-call system stays intact.
Compliance reporting then runs against the live state, not the catalog. AWS Config Rules continuously check tagging compliance.
Drift gets surfaced to platform dashboards weekly. Teams see their own compliance score. Remediation is self-service.
This approach shifts ownership from an administrative task to an engineering constraint. It does not rely on discipline. It relies on design.
FASTER INCIDENTS. CLEANER AUDITS. NO ARCHAEOLOGY
The operational gap between these two approaches is not theoretical.
Teams that enforce ownership at provisioning resolve incidents faster. The on-call contact is visible in the resource tag, surfaced by the monitoring tool, and reachable in under two minutes. There is no Slack archaeology.
Ownership is queryable. It is attached to the resource, not stored in someone’s memory. When auditors ask about access controls or cost attribution, the answer is a tag report.
Cost anomalies get routed to the right team without a platform team investigation.
A platform team that enforces ownership is running governance as a system. A platform team that documents ownership is running governance as a hope. The first team gets the budget. The second team gets audit findings.
VISIBILITY FIRST. ENFORCEMENT SECOND. IN THAT ORDER.
The path from documentation to enforcement does not require rebuilding your platform. It requires picking the right starting point.
Pull an AWS Config report or use Resource Groups Tag Editor to identify every resource missing an owner tag. Show that report to your engineering leads. Not as a compliance finding. As a shared problem.
Then apply SCP-based tag enforcement to new accounts first. Existing accounts get a remediation window of 30 to 60 days. The Terraform modules in your golden path should include required tags by default, so new services deploy compliant from day one.
Wire ownership to function next. Link your on-call rotation to a team alias that appears in the service’s owner tag. When PagerDuty fires, the routing is automatic.
Surface each team’s ownership compliance score in your developer portal. Teams respond to scorecards they can see. They do not respond to spreadsheets they cannot find.
This shift takes one to two quarters. It is a governance layer applied to the infrastructure you already own.
RUN THIS CHECK THIS WEEK
Pull your AWS Resource Groups Tag Editor report across all accounts. Filter for resources missing an “owner” or “team” tag.
If more than 20% of resources lack an owner declaration, you will have a gap that will surface in your next audit or incident.
Pick one account. Apply SCP-based tag enforcement only to new resources. Update your Terraform module defaults to include owner, team, environment, and cost-center tags. Ship that in the next sprint.
If your team does not have a standard Terraform module or a defined set of required tags, that is the starting point.
If this resonated, you’re probably already picturing where your own ownership model would crack during an incident or audit.
You can close that gap in two ways:
Assemble the mechanisms yourself from this essay, AWS docs, and a few painful incidents, or
Start from a baseline that has already survived real FedRAMP / HIPAA / ISO environments.
The paid version of The Cloud Playbook takes essays like this and turns them into implementation kits.
For this issue, paid subscribers get:
A 90‑day rollout plan for enforcing ownership at provisioning
Example AWS Tag Policies and SCPs to block untagged resources
AWS Config rules to surface ownership drift weekly
An ownership scorecard spec you can drop into your portal
If enforcing ownership like this doesn’t save you more than the subscription in one incident or one audit cycle, you should cancel.
If you want that kit, upgrade to the paid newsletter here
Whenever you’re ready
There are two ways I can help you further:
Get the AWS Platform Predictability Starter Kit (Free)
Four short tools to baseline where your platform is strong vs where it’s bleeding:5‑minute predictability checklist
“Where are we bleeding?” team scorecard
Platform risk radar with 12 early‑warning signals
10 executive questions with weak vs strong answers + debrief worksheet
Most leaders run through these in a week of normal meetings and come away with a clear “top 3” to fix.
→ Grab the Starter Kit: https://thecloudplaybook.gumroad.com/l/aws-platform-predictability-starter-kitKeep getting essays like this every week
Stay on the free list, apply one check per week, and share this with your platform peers so you’re solving the same problems with the same language.
Get in touch
You can find me on LinkedIn or X.
If you would like to request a topic to read, please feel free to contact me directly via LinkedIn or X.