
TCP #104: When teams route around your standards, the standards are wrong.
Not the teams. Here is how to tell the difference.

You can also read my newsletters from the Substack mobile app and be notified when a new issue is available.

Most platform conversations eventually hit this fork.
One side wants consistency.
One runtime. One deployment pipeline. One observability stack. One way to provision infrastructure.
The other side wants freedom.
Teams should choose the tools that fit their problem. Constraints slow engineers down. Autonomy produces better outcomes.
Both positions are partially right.
Both, when taken to extremes, produce systems that fail in predictable ways.
Here is how I honestly evaluate the trade-off.
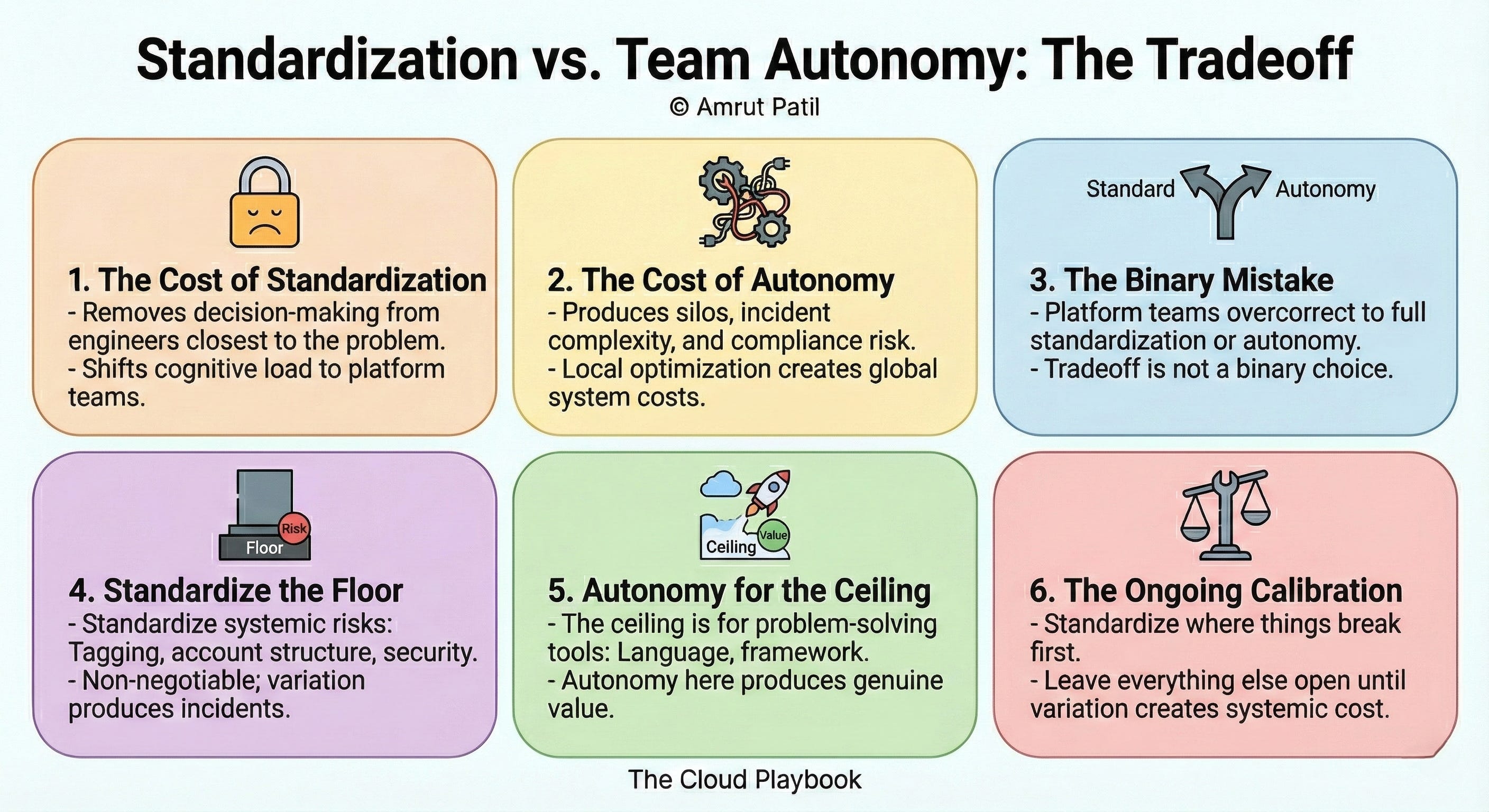
STANDARDIZATION HAS A REAL COST
Start with what standardization actually takes from teams.
When a platform mandates a single runtime, a single pipeline, and a single logging format, it removes decision-making from engineers closest to the problem.
Sometimes, that decision-making was producing divergence that the platform could not support. Sometimes it was producing genuine innovation, but the platform was killed.
Standardization shifts cognitive load from individual teams to the platform team. Engineers stop thinking about infrastructure choices and start working within guardrails.
That is the intended outcome.
But guardrails set in the wrong place constrain the right behaviors alongside the wrong ones.
A Python team forced into a Java deployment pipeline does not get faster. A team building real-time data pipelines constrained by a batch-processing standard does not become more reliable.
Standardization applied without context produces friction that engineers route around, which is worse than no standard at all.
The cost of standardization is real. It is measured in slowed onboarding for edge cases, frustrated senior engineers who know a better path exists, and workarounds that accumulate outside the platform’s visibility.
Ignore that cost, and you build a platform that teams tolerate instead of one they trust.
AUTONOMY HAS A REAL COST TOO
Autonomy sounds right because it respects engineering judgment.
Teams pick the tools they know. They move faster in familiar environments. They own their decisions and their outcomes.
In theory, this produces better systems built by motivated engineers.
In practice, unconstrained autonomy produces something else entirely.
Twelve teams. Eight languages. Six deployment mechanisms. Four observability stacks.
No shared on-call playbook. No consistent tagging. No standard for how infrastructure gets provisioned or decommissioned.
When an incident crosses service boundaries, no single engineer understands the full system.
When a compliance audit requires evidence across all services, each team produces it differently.
When a senior engineer leaves, their infrastructure choices leave with them.
Autonomy without boundaries does not produce ownership. It produces silos.
Each team optimizes locally, and the system pays the cost globally.
In regulated environments, the cost is sharper.
One team’s non-standard deployment mechanism produces an audit finding that blocks the entire organization’s certification. One team’s custom observability tooling creates a gap in the evidence library.
The audit does not care that the team had good reasons.
Autonomy is not free. Its cost is paid in coordination overhead, incident complexity, and compliance risk.
WHERE MOST TEAMS GET IT WRONG
The mistake is treating this as a binary choice.
Platform teams that have been burned by inconsistency push toward full standardization. Platform teams accused of slowing engineers down push toward full autonomy.
Both overcorrect. Both create the failure mode they were trying to avoid.
Full standardization produces a platform that works for 80% of use cases and creates an adversarial relationship with the 20% that do not fit.
Engineers in that 20% stop engaging with the platform and build outside it. The platform team loses visibility into what those teams are running, which is exactly the opposite of what standardization was supposed to produce.
Full autonomy produces a platform that nobody calls a platform.
It is just a collection of individual team choices with a shared AWS account. When something breaks at the system level, nobody owns it.
The mistake is picking a pole and defending it.
The trade-off is not between standardization and autonomy. It is figuring out which layer of the stack each one applies to.
HOW I EVALUATE IT
The frame I use: standardize the floor, not the ceiling.
The floor is everything that creates systemic risk when it varies.
Tagging. Account structure. Network topology. Security baselines. Compliance controls. Deployment gates.
These are non-negotiable. Variation here does not produce innovation. It produces incidents, audit findings, and cost spikes that nobody can attribute.
The ceiling is everything teams use to solve their specific problem.
Language. Framework. Internal libraries. Caching strategy. Database choice within approved types.
Autonomy here produces genuine value. Engineers make better decisions when they understand the problem space, and they understand it better than the platform team does.
The question I ask for any proposed standard: what is the systemic cost of variation here?
If variation in this layer creates on-call complexity, compliance gaps, or cost-assignment issues, standardize it. The cost of enforcement is lower than the cost of the failure mode.
If variation in this layer reflects legitimate differences in team context and problem type, leave it alone. The platform’s job is not to eliminate judgment. It is to channel it toward the right decisions.
One more signal: if a standard requires significant ongoing enforcement, it is probably set at the wrong layer.
Good standards are adopted because they reduce friction, not because they are mandated. If teams are routing around a standard consistently, the standard is wrong, not the teams.
A second signal: watch where senior engineers spend their time.
If your best engineers are spending hours navigating platform constraints to do work that the platform should be making simple, the standard is in the wrong place.
If they are spending hours cleaning up after teams that went off-road, autonomy is in the wrong place.
The answer to this tradeoff is not a policy. It is an ongoing calibration.
Your platform design should reflect the actual failure modes your organization has experienced, not the theoretical ones you are trying to prevent. Start with where things have broken. Standardize there first. Leave everything else open until you have evidence that variation is creating systemic cost.
Most teams skip this conversation because it requires admitting that both standardization and autonomy have failed them at some point.
Naming that honestly is the starting point for building a platform that does neither.
The Cloud Playbook publishes every Wednesday and Sunday. In the paid playbook, I walk through how to actually map your current stack into ‘floor vs ceiling’ and codify it into standards and exception paths.
Whenever you’re ready, there are 2 ways I can help you:
Free guides and helpful resources: https://thecloudplaybook.gumroad.com/
Get certified as an AWS AI Practitioner in 2026. Sign up today to elevate your cloud skills. (link)
That’s it for today!
Did you enjoy this newsletter issue?
Share with your friends, colleagues, and your favorite social media platform.
Until next week — Amrut
Get in touch
You can find me on LinkedIn or X.
If you would like to request a topic to read, please feel free to contact me directly via LinkedIn or X.