
TCP #89: Strands Agents: The Production-Ready Framework You’re Not Using (But Should Be)
The orchestration framework that actually ships to production

You can also read my newsletters from the Substack mobile app and be notified when a new issue is available.

I wasted three weeks building an agent framework from scratch.
Custom retry logic, hand-rolled observability, and error handling that worked in dev but fell apart in production.
Then I discovered Strands Agents, and everything clicked.
This isn’t another “AI agent framework” that looks impressive in demos but crumbles under real-world load.
This is the framework that handles the unglamorous 80% of agent development: orchestration, error handling, and observability that separate proof-of-concepts from production systems.
Here’s what nobody tells you about building agents that actually work.
The Problem With Most Agent Frameworks
Most agent frameworks force you into a trap: hardcoded task flows that seem elegant until requirements change. And requirements constantly change.
You write beautiful orchestration logic that routes tasks perfectly, until a new business rule arrives. Now you’re rewriting control flow, adjusting conditionals, and hoping you didn’t break existing paths. Your “intelligent” agent becomes a maintenance nightmare wrapped in LLM calls.
Strands flips this paradigm entirely.
The LLM handles planning and orchestration. You define tools and business logic. When requirements evolve, you add tools, not rewrite orchestration code.
This architectural shift changes everything about how agents scale in production environments.
What Strands Actually Does (And Why It Matters)
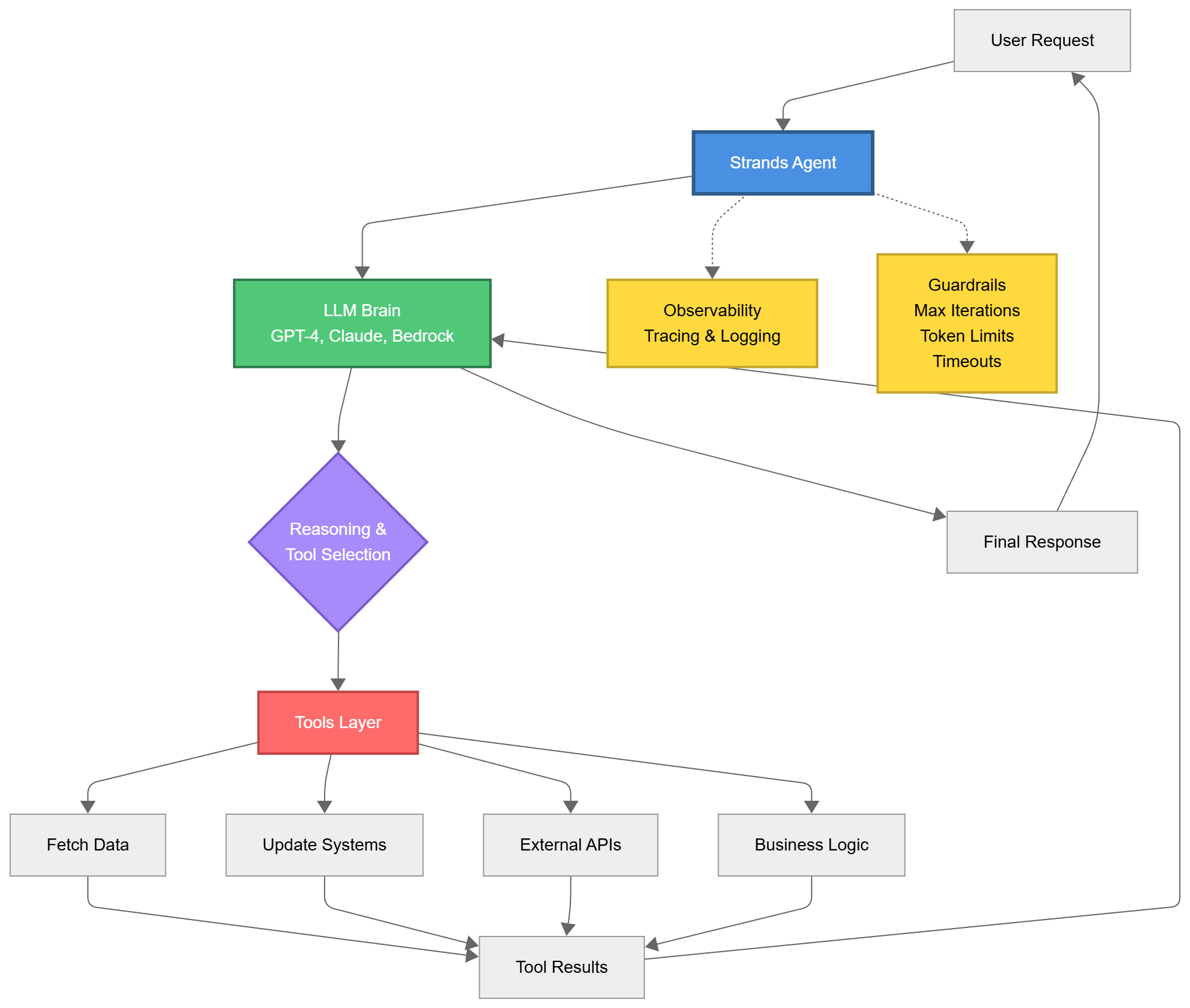
Strands Agents implements model-driven orchestration. Your agent reasons about which tools to use, in what order, and how to handle edge cases, all dynamically, based on the task at hand.
You’re not writing “if task A, call function X, then check result, then maybe call Y.” You’re defining capabilities as tools, and the LLM intelligently coordinates execution.
Built by AWS but designed to work with any LLM provider (OpenAI, Anthropic, Bedrock, even local models), Strands focuses on three things most frameworks treat as afterthoughts:
Production observability that actually helps you debug
Resource management that prevents runaway costs
Error handling that doesn’t require custom try-catch pyramids
This isn’t theory. This is infrastructure that ships to production and stays there.
Getting Started: The Critical First Steps
Installation is straightforward: pip install strands-agents
But here’s where most developers make their first mistake: they treat Strands like LangChain or AutoGPT.
It’s not.
Strands is opinionated about observability, error handling, and resource management. Fight these opinions, and you’ll struggle.
Embrace them, and you’ll ship faster.
The minimal agent requires three components:
An LLM client (OpenAI, Anthropic, Bedrock)
Tool definitions (Python functions decorated with
@tool)An agent instance that coordinates everything
Here’s what this looks like in practice:
from strands import Agent, tool
@tool
def fetch_user_order_history(user_id: str) -> dict:
“”“Retrieves complete order history for a user”“”
# Your business logic here
return {”orders”: [...], “total_spent”: 1250.00}
agent = Agent(
model=”claude-3-sonnet”,
tools=[fetch_user_order_history],
max_iterations=5
)
Notice max_iterations=5. This is non-negotiable for production. We’ll return to why.
Tools: Your Competitive Advantage
Tools are where Strands shines, and where most implementations fail.
The pattern is simple: write a Python function, add the @tool decorator, and Strands handles everything else. It generates descriptions, manages calling conventions, and handles type validation.
But the gotcha that breaks 70% of first attempts? Tool naming and descriptions.
Bad tool definition:
@tool
def get_data(id: str) -> dict:
“”“Gets data”“”
The LLM has no context. When should it call this? What data? This tool will be misused or ignored.
Good tool definition:
@tool
def fetch_user_order_history(user_id: str) -> dict:
“”“Retrieves complete purchase history for a specific user,
including order dates, amounts, and status. Use when customer
asks about past orders or purchase patterns.”“”
Specificity matters.
The LLM uses your docstring to decide when to invoke tools. Vague descriptions lead to the wrong tool selection, which confuses users and frustrates developers.
Three tool design principles that separate working agents from broken ones:
Descriptive names that indicate purpose (
calculate_shipping_costnotcalc)Detailed docstrings that explain when and why to use the tool
Clear return types so the LLM knows what data to expect
Your tools determine agent capability. Invest time here.
The Observability Win Nobody Talks About
When your agent breaks in production, and it will, you need to know three things instantly:
Which tool failed
What the LLM was thinking when it made that decision
Where context was lost or misinterpreted
Most frameworks leave you blind. Strands builds observability into the core architecture.
Enable tracing and you see the complete decision chain: every tool considered, every parameter evaluated, every branch explored. This isn’t just logging. This is a structured insight into LLM reasoning.
In practice, this means debugging shifts from “why did my agent do that?” to “here’s exactly where the logic diverged.” You’ll fix production issues in minutes instead of hours.
The configuration is simple:
agent = Agent(
model=”claude-3-sonnet”,
tools=[...],
verbose=True, # Detailed execution logs
trace_enabled=True # Structured decision traces
)
This overhead is negligible in production but invaluable during incidents.
Multi-Agent Patterns That Actually Work
The hype around multi-agent systems promises magical collaboration. The reality is messier.
Here’s the pattern that works in production: one agent per domain, coordinated through a simple orchestrator.
Example architecture:
Research Agent: Gathers information, queries databases, calls APIs
Execution Agent: Takes actions, updates systems, triggers workflows
Validation Agent: Checks outputs, verifies constraints, handles quality control
Each agent has focused tools and a clear responsibility. The coordinator routes tasks based on intent, not complex negotiation protocols.
Start simpler than you think necessary. One well-tooled agent with 10 quality tools outperforms five poorly-defined agents with overlapping responsibilities every single time.
The mistake is assuming that more agents equals more capability. More agents equal more coordination overhead. Add agents only when single-agent complexity becomes unmanageable.
The Production Pitfall That Destroys Budgets
Agent loops can run indefinitely. Your LLM decides “I need more information,” calls a tool, processes the result, decides it needs still more information, and continues—burning tokens and racking up costs.
This is the production nightmare that hits teams after their first spike in traffic.
Strands makes loop control configurable, but defaults are lenient for development convenience. Tighten them before deployment:
agent = Agent(
model=”claude-3-sonnet”,
tools=[...],
max_iterations=5, # Hard stop after 5 tool calls
max_execution_time=30, # 30-second timeout
token_limit=4000 # Budget per request
)
Monitor these metrics in production. When max_iterations is consistently hit, either your tools aren’t providing enough information per call, or your task complexity exceeds a single agent's capability. Both are fixable, but you need visibility to diagnose.
Set conservative limits initially. You can always relax them based on actual usage patterns. Starting permissive and tightening later requires explaining cost spikes to stakeholders.
Memory Management: The Invisible Performance Killer
Conversation history grows linearly with interaction length. Each exchange adds tokens. Eventually, you hit context window limits, and your agent loses critical information.
Strands handles truncation automatically, but you control the strategy—and the wrong strategy breaks user experience.
Three approaches that work:
1. Stateless agents (best for independent tasks)
Clear history between requests. Each interaction is self-contained. Perfect for one-shot queries like “What’s the weather in Boston?”
2. Summarization (best for long sessions)
Periodically compress conversation history into summaries. Keep recent exchanges verbatim, summarize older context. Works for customer support sessions that span multiple issues.
3. Selective retention (best for complex workflows)
Keep only task-relevant context. Drop small talk, keep tool results and decisions. Requires more configuration but maximizes effective context usage.
Choose based on your use case. Don’t default to keeping everything; you’re wasting context window on information the agent doesn’t need.
Model Selection: The 40% Cost Reduction Nobody Implements
Here’s a secret: you don’t need your most powerful model for every step.
Tool selection (“which function should I call?”) requires less reasoning than complex analysis. Route planning is simpler than creative writing. Yet most implementations use the same model for everything.
Strands supports model switching mid-conversation. This cuts costs by 40% in real-world production usage:
Smaller models (GPT-3.5, Claude Instant) for tool selection and routing
Larger models (GPT-4, Claude Sonnet) for complex reasoning and generation
Local models for sensitive data that can’t leave your infrastructure
The pattern:
# Tool selection with smaller model
agent.select_tool(model=”gpt-3.5-turbo”)
# Execute with appropriate model for complexity
agent.reason(model=”claude-3-sonnet”)
This optimization alone often pays for the engineering time to implement it within the first month of production operation.
Debugging: What to Check When Your Agent “Doesn’t Understand”
When users report “the agent didn’t understand my request,” 90% of the time, it’s one of three fixable issues:
1. Unclear tool descriptions
The LLM can’t select the right tool because your docstrings are vague.
Fix: rewrite with explicit use cases and examples.
2. Missing context
The agent lacks the information necessary to complete the task.
Fix: either add tools to fetch that context, or adjust your system prompt to request clarification.
3. Conflicting instructions
Your system prompt says one thing, your tool descriptions say another.
Fix: align your messaging. The LLM will follow the clearest directive.
Enable verbose logging during debugging.
You’ll see the LLM’s chain of thought, what it considered, why it chose specific tools, and what information it thought it needed. This transparency transforms debugging from guesswork to systematic problem-solving.
Test tools independently before integration. A tool that works perfectly in isolation but fails in an agent context usually has a description mismatch, not a logic error.
Real-World Implementation: Customer Support Agent
Theory is worthless without application. Here’s a production-ready customer support agent built with Strands, 40 lines replacing 400+ lines of custom orchestration:
Capabilities:
Route query based on intent
Fetch user context and history
Generate personalized responses
Escalate complex issues to humans
Track resolution metrics
Tools defined:
fetch_user_profileget_order_statussearch_knowledge_basecreate_support_ticketescalate_to_human
The agent dynamically reasons through the workflow. A billing question triggers different tools than a technical issue. Context from early in the conversation informs later decisions. Escalation occurs when the agent detects that it’s outside its capabilities.
No hardcoded if-then chains. No brittle routing logic. Just tools and coordination.
When business rules change (“now we need to check warranty status before offering replacements”), you add a tool. Not rewrite orchestration.
This is the power of model-driven coordination.
Testing Strategy: Ship With Confidence
Agents are probabilistic systems. Traditional testing approaches don’t translate directly. Here’s what works:
Unit tests: Test tools independently with mock inputs. Ensure business logic works correctly regardless of how the agent invokes it.
Integration tests: Use real LLMs with representative queries. Strands makes it trivial to mock LLM responses for predictable testing, but you need real model tests to catch prompt issues.
Regression tests: Capture successful agent interactions as test cases. When you modify tools or prompts, verify these golden paths still work.
The mistake teams make: skipping integration tests because “LLM responses are unpredictable.” Yes, they are. That’s why you test with multiple queries that should trigger the same tool path. Variance in language, consistency in behavior.
Build your test suite before production. Adding tests after your first production incident is learning the hard way.
When NOT to Use Strands
Strands isn’t universal. Three scenarios where simpler alternatives work better:
1. Simple prompt-response applications
If you’re generating text from a prompt with no tool calling, you’re over-engineering. Use the LLM API directly.
2. Deterministic workflows
If your process is completely predictable (”always do A, then B, then C”), use AWS Step Functions or Apache Airflow. You don’t need LLM reasoning for deterministic orchestration.
3. Extreme latency requirements
Agent loops add latency. Each tool call requires LLM reasoning. If you need sub-100ms responses, agents aren’t your solution.
Strands shines when you need dynamic reasoning, complex tool orchestration, and production observability. Know the difference between “this would be cool with an agent” and “this actually needs agent capabilities.”
The Framework Fatigue Problem
A new agent framework launches every week. Most disappear within months. Engineering teams are exhausted from evaluating options.
Strands is different for three reasons:
1. AWS backing means long-term support and integration with cloud services
2. Production focus over demo appeal, observability and error handling are first-class features
3. Active maintenance with regular updates addressing real-world usage patterns
It’s not the flashiest framework. It doesn’t promise AGI or autonomous everything. It’s the framework that won’t break your production deployment at 2 am because the maintainer lost interest.
Boring reliability beats exciting demos when you’re shipping to customers.
Final Thoughts
Agent orchestration is complex. Strands doesn’t eliminate that complexity; it makes it manageable.
You still need to design good tools. You still need to handle edge cases. You still need to monitor production behavior.
But you don’t need to build orchestration infrastructure from scratch. You don’t need custom observability. You don’t need to debug inscrutable tool-calling chains.
Strands handles the infrastructure layer so you can focus on the business logic that differentiates your application.
Three weeks ago, I was writing custom retry logic. Today, I’m shipping agents to production.
The difference? Focusing on problems that matter instead of reinventing solved problems.
That’s what good infrastructure does.
Whenever you’re ready, there are 3 ways I can help you:
Want to build automated, AI-powered businesses without quitting your job? Join my free community: The AI Business Playbook
Free guides and helpful resources: https://thecloudplaybook.gumroad.com/
Get certified as an AWS AI Practitioner in 2025. Sign up today to elevate your cloud skills. (link)
That’s it for today!
Did you enjoy this newsletter issue?
Share with your friends, colleagues, and your favorite social media platform.
Until next week — Amrut
Get in touch
You can find me on LinkedIn or X.
If you would like to request a topic to read, please feel free to contact me directly via LinkedIn or X.