
TCP #116: Most teams don't have a technical debt problem.
They have a decision debt problem. The distinction changes what you measure, build, and protect.

Most engineering leaders talk about technical debt as if it is a coding problem.
It is not.
The systems that break expensively, the ones that consume quarters of remediation work, delay IPOs, and create the audit findings nobody can explain, almost never break because the code was bad.
They break because the decisions behind the code were never documented.
That is a different problem. And it requires a different fix.
How Most Engineering Leaders Frame The Problem
Technical debt is the dominant frame for platform problems.
It is a useful shortcut. But it points to the wrong layer.
When leaders say “we have technical debt,” they usually mean one of three things:
The codebase is harder to change than it should be
The system is harder to reason about than it should be, or
The architecture does not match the current scale of the organization.
All of those things can be true.
But they are usually symptoms of a deeper problem: the team cannot explain why the system works the way it does, because the decisions that produced it were made informally, without documentation, by people who may no longer be at the company.
The technical debt is real. But it is downstream of the decision debt that created it.
Why Framing This As Technical Debt Produces The Wrong Fix
The technical debt frame leads to the same response: allocate engineering time to refactor, migrate, or modernize. That work often creates genuine value.
It does not prevent the same problem from recurring.
Teams that pay down technical debt without addressing the decision practices that created it are running a maintenance loop. They clean up the current accumulation. New decision debt creates new technical debt. The cycle repeats.
The root issue is structural: most engineering organizations do not treat decisions as artifacts that need to be created, stored, and maintained. They treat decisions as conversations that produce outcomes.
Decisions made in conversations evaporate. The outcome, the code, the architecture, and the policy persist.
The reasoning does not.
Three months later, a new engineer inherits the system and asks why it works the way it does. The answer is: nobody knows.
That is decision debt.
The Better Frame: Decisions Are Durable Artifacts
Decision debt is the accumulation of choices that were made but not documented: the AWS account structure rationale, the secrets management approach, the deployment ownership model, and the trade-offs accepted under time pressure.
Unlike technical debt, decision debt is invisible.
You cannot run a linter against it. It does not surface in code reviews. It shows up during an audit, a compliance review, a post-incident retrospective, or a due diligence process when someone needs to understand why the platform works the way it does, but no one can answer.
Reframing from technical debt to decision debt changes what you measure, what you build, and what you protect.
What Changes When You See It This Way
When you treat decision debt as the primary problem, the fix shifts from code to documentation, but not the kind of documentation most teams write.
Not README files. Not wiki pages that go stale in 90 days.
The artifact that matters is a decision record: a brief, durable document that captures what was decided, what the alternatives were, why this option was chosen, and what conditions would cause you to revisit it.
Architecture Decision Records (ADRs) are the most common format. The format matters less than the habit.
Platform teams that practice decision documentation accumulate something more valuable than clean code: they accumulate institutional reasoning.
When an auditor asks why the platform has three separate IAM policies, the team with decision records can answer in 10 minutes. The team reconstructs the rationale without them over six weeks.
When a new CTO joins and asks why the organization chose multi-account over single-account AWS, the team with decision records shows them the 2023 evaluation. The team, without them, shrugs.
The gap compounds at every leadership transition, every compliance review, and every architecture evolution.
One Action: Start The Record
Identify the five most consequential platform decisions made in the last 24 months.
For each, write a single paragraph capturing: what was decided, what was rejected, why, and what would cause you to revisit it. Date it. Name the decision owner.
Store it somewhere that the next engineer and the next auditor can find it.
That is your starting point for a decision debt practice. It will not eliminate the backlog overnight. But it will stop the accumulation.
What to do this week
Pull your last three post-incident retrospectives.
For each incident, identify whether the root cause was a technical failure or a decision that was made without documentation.
If you cannot answer that question, the decision record does not exist — and the same incident will recur under different conditions.
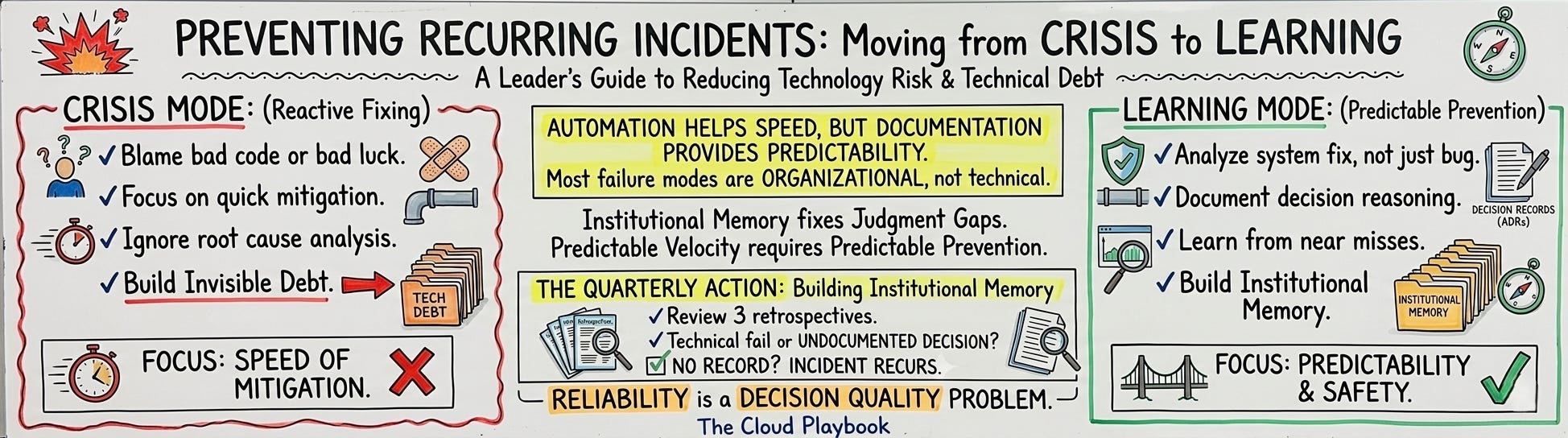
Platform reliability is not a code quality problem. It is a decision quality problem. The documentation is the practice.
Every time I’ve worked through a platform audit or due diligence process, the hardest questions to answer are not technical.
They are: “Why does this work the way it does?” and “Who decided this?”
Teams with decision records answer in minutes. Teams without them answer in months.
Tools make noise. Boundaries create signal.
I build platforms by drawing the right lines between teams, not by adding more stacks.
Upgrade If You Need Implementation, Not Just Ideas
If you’re using these emails to guide real decisions on your platform, you’ll get more leverage from the paid version of The Cloud Playbook.
The free newsletter gives you patterns and language.
The paid newsletter turns those patterns into implementation kits you can ship inside a quarter:
Concrete rollout plans (90‑day roadmaps for each pattern)
Templates and checklists (policies, runbooks, tagging schemes, review checklists)
Real examples from high‑stakes AWS environments (what we actually shipped and why)
If the paid side doesn’t save you more than the subscription in one incident, audit cycle, or bad migration you avoid, you should cancel and keep the playbooks.
That’s it for today!
Did you enjoy this newsletter issue?
Share with your friends, colleagues, and your favorite social media platform.
Until next week — Amrut
Get in touch
You can find me on LinkedIn or X.
If you would like to request a topic to read, please feel free to contact me directly via LinkedIn or X.