
TCP #83: The LLMOps Lifecycle: A Complete Implementation Guide for Production AI Systems
How to build robust LLM operations that scale without breaking your budget or your team

You can also read my newsletters from the Substack mobile app and be notified when a new issue is available.

Last month, I witnessed a devastating AI project failure that cost a mid-sized company six months of development time. The culprit wasn't the model, the data, or even the team's technical skills. It was the complete absence of a structured LLMOps lifecycle.
According to recent industry analysis, 73% of LLM deployments fail to reach production or fail within the first 90 days.
The surviving 27% share one critical trait: they follow a systematic approach to LLM operations that treats AI as a product, not an experiment.
In today’s newsletter, I break down the complete LLMOps lifecycle into 10 distinct phases, each with actionable steps. Each phase includes real-world implementation strategies, common failure patterns, and specific troubleshooting techniques that can save you months of debugging and thousands in unnecessary costs.
Let’s dive in.
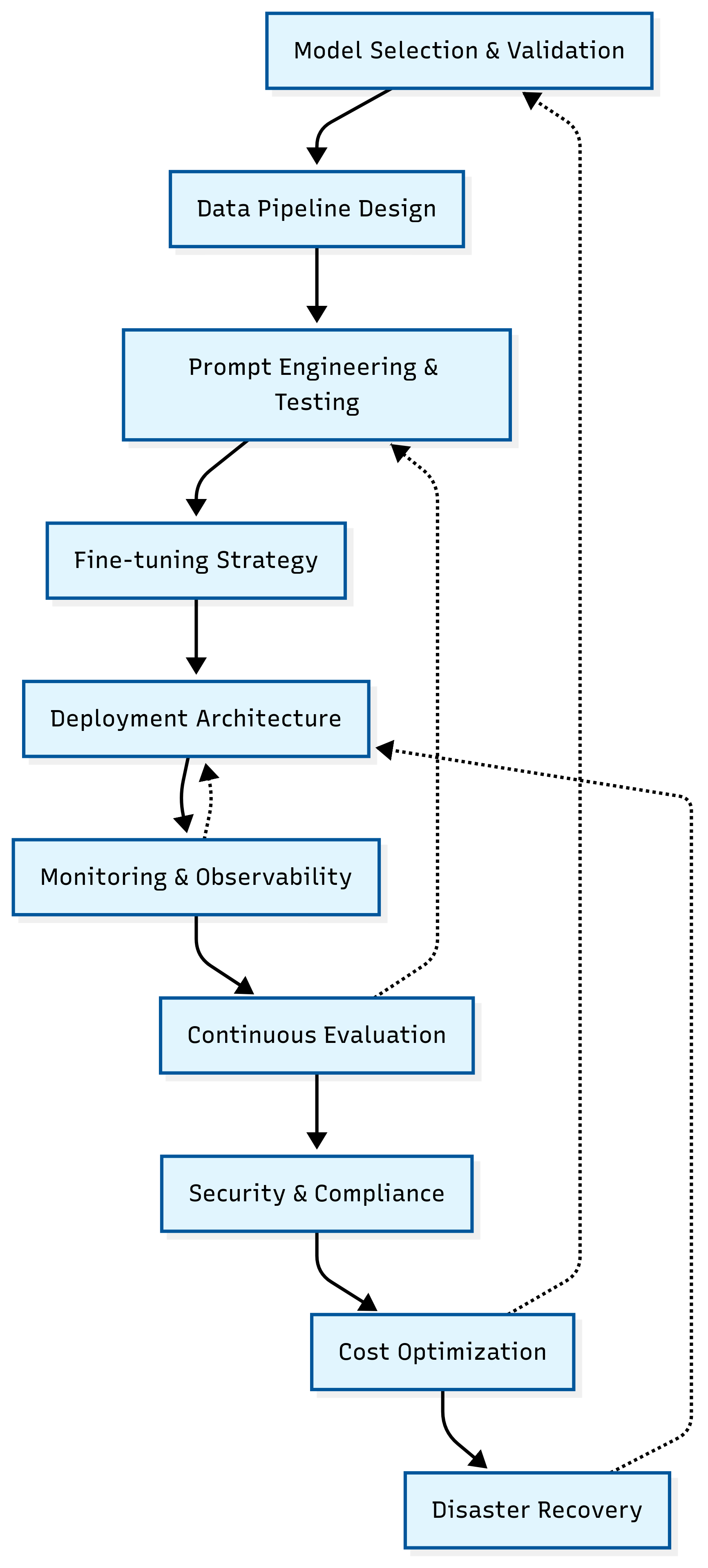
Phase 1: Strategic Model Selection & Validation
The Foundation Decision That Determines Everything
Your model selection isn't just a technical choice; it's a business strategy that impacts every downstream decision. The most expensive mistake teams make is choosing a model based on benchmarks rather than business requirements.
The Selection Framework:
Performance Requirements Analysis:
Define your minimum accuracy threshold based on business impact
Establish latency requirements (real-time vs. batch processing)
Calculate your cost ceiling per request
Identify your data privacy and compliance constraints
Practical Validation Process:
Create a representative test dataset of 500-1000 examples from your actual use cases
Run comparative evaluations across 3-5 candidate models
Measure total cost of ownership, not just API costs (include fine-tuning, infrastructure, monitoring)
Test edge cases that represent your worst-case scenarios
Red Flags to Avoid:
Selecting based solely on leaderboard performance
Ignoring inference costs in favor of "best" accuracy
Failing to test multilingual requirements early
Underestimating the impact of context window limitations
Implementation Tip: Build a simple evaluation harness that you can rerun as new models become available. The AI landscape changes monthly—your selection process should be repeatable.
Phase 2: Robust Data Pipeline Design
Where 90% of Projects Die Silently
Data quality issues in traditional ML are debugging challenges. In LLM systems, they're existential threats. Poor data quality doesn't just reduce accuracy—it can cause hallucinations, biased outputs, and complete system failures.
The Four Pillars of LLM Data Architecture:
1. Data Validation Schemas: Implement automated validation at ingestion:
Schema validation for structured inputs
Content filtering for toxic or inappropriate material
Format consistency checks (JSON structure, required fields)
Length validation (within model context limits)
2. Version Control Strategy: Treat datasets like code:
Semantic versioning for dataset releases
Change logs documenting modifications
Rollback capabilities for problematic updates
Branch-based development for experimental datasets
3. Real-Time Drift Detection: Monitor your data distribution continuously:
Statistical measures of input distribution changes
Semantic drift detection using embedding distances
Alert thresholds based on historical variance
Automated dataset refresh triggers
4. Quality Assurance Automation: Build quality gates that prevent bad data from reaching production:
Duplicate detection and removal
Consistency checks across data sources
Automated labeling quality scores
Human-in-the-loop validation for edge cases
Critical Implementation Detail: Set up separate data pipelines for training, validation, and production inference. Cross-contamination between these environments is one of the fastest ways to create overconfident models that fail in production.
Phase 3: Systematic Prompt Engineering & Testing
Your Model's Operating System
Prompts aren't just instructions; they serve as the interface between your business logic and the model's capabilities. A systematic approach to prompt engineering can improve performance by 40-60% without requiring model changes.
The Scientific Approach to Prompt Development:
Structured Experimentation:
Version control every prompt variation
A/B test prompts on statistically significant sample sizes
Track success rates by specific use case and user segment
Document what works and what fails spectacularly
Advanced Prompt Techniques:
Chain-of-thought prompting for complex reasoning tasks
Few-shot examples selected algorithmically, not randomly
Role-based prompting to activate specific model behaviors
Constraint specification to prevent unwanted outputs
Fallback Strategy Architecture: Design your prompts with degradation in mind:
Primary prompt optimized for accuracy
Simplified fallback for edge cases
Generic safety prompt for unknown scenarios
Error handling prompts for system failures
Testing Methodology: Create prompt test suites similar to unit tests:
Positive test cases (expected good outcomes)
Negative test cases (should be rejected)
Edge cases (boundary conditions)
Adversarial examples (prompt injection attempts)
Pro Tip: Build a prompt playground environment where you can test changes safely before deployment. Include automatic regression testing to ensure new prompts don't break existing functionality.
Phase 4: Strategic Model Fine-Tuning
When to Invest, When to Iterate
Fine-tuning is expensive and time-consuming. The key is knowing when it's worth the investment versus when prompt engineering or retrieval-augmented generation (RAG) will solve your problem more quickly and cost-effectively.
The Decision Matrix:
Dataset Size Guidelines:
<100 examples: Focus on prompt engineering and few-shot learning
100-1000 examples: Consider parameter-efficient fine-tuning (LoRA)
1000-10,000 examples: Evaluate full fine-tuning vs. specialized prompting
>10,000 examples: Full fine-tuning becomes cost-effective
Fine-Tuning Strategy Framework:
Parameter-Efficient Approaches:
LoRA (Low-Rank Adaptation): Reduces trainable parameters by 90%
Prefix tuning: Learns task-specific prefixes
Adapter layers: Small modules added to the existing architecture
Quality Control Process:
Hold-out validation sets that mirror production distribution
Progressive evaluation during training to prevent overfitting
Comparative benchmarking against base model performance
Cost-benefit analysis comparing the improvement gains to training costs
Common Fine-Tuning Mistakes:
Training on datasets that don't match production distribution
Over-tuning on small datasets leads to memorization
Ignoring the base model's existing capabilities
Failing to evaluate diverse test scenarios
Implementation Reality Check: Fine-tuning often improves performance by 10-20%. Ensure this improvement justifies the 5- to 10-fold increase in operational complexity.
Phase 5: Production-Ready Deployment Architecture
Scaling from Prototype to Production
The gap between a working demo and a production system is where most AI projects fail. Your deployment architecture must handle not just happy-path scenarios, but the chaos of real-world usage patterns.
Core Infrastructure Components:
Load Balancing Strategy:
Round-robin distribution across multiple model instances
Weighted routing based on model performance and cost
Geographic load balancing for global applications
Circuit breaker patterns to isolate failing instances
Caching Architecture: Implement multi-level caching to reduce costs and latency.
Response caching for identical queries
Semantic caching for similar but not identical requests
Partial result caching for complex multi-step operations
Cache invalidation strategies for dynamic content
Auto-Scaling Configuration: Design scaling policies that respond to LLM-specific metrics:
Token throughput rather than just request volume
Queue depth for asynchronous processing
Cost thresholds to prevent runaway expenses
Model warm-up time considerations for new instances
Resilience Patterns:
Graceful degradation to simpler models during high load
Request queuing with priority-based processing
Timeout configurations that balance user experience and cost
Retry logic with exponential backoff for transient failures
Security Integration:
API gateway with rate limiting and authentication
Input sanitization to prevent prompt injection
Output filtering for content policy compliance
Audit logging for compliance and debugging
Phase 6: Comprehensive Monitoring & Observability
Making the Invisible Visible
LLM systems are notoriously difficult to debug because the "logic" is embedded in neural network weights. Comprehensive monitoring transforms mysterious failures into actionable insights.
The Four Pillars of LLM Observability:
1. Performance Metrics: Track metrics that matter for LLM systems:
Latency percentiles (P50, P95, P99) for user experience
Token utilization and cost per request
Throughput measured in tokens per second
Error rates by error type and user segment
2. Quality Metrics: Implement automated quality assessment:
Semantic similarity between expected and actual outputs
Hallucination detection using fact-checking techniques
Bias monitoring across demographic segments
User satisfaction through implicit and explicit feedback
3. Business Metrics: Connect technical performance to business outcomes:
Task completion rates for specific use cases
User engagement and retention metrics
Cost per successful interaction
Revenue impact of AI-driven features
4. System Health Metrics: Monitor the infrastructure supporting your models:
GPU utilization and memory consumption
Network latency between system components
Queue depths and processing delays
Resource contention and scaling events
Alert Strategy: Design alerts that prevent alert fatigue:
Tiered alerting based on severity and business impact
Predictive alerts that fire before problems become critical
Contextual alerts that include troubleshooting suggestions
Alert correlation to prevent spam during system-wide issues
Dashboard Design: Create dashboards for different stakeholders:
Executive dashboards focusing on business metrics and costs
Engineering dashboards emphasizing system health and performance
Product dashboards highlighting user experience and feature adoption
Phase 7: Continuous Evaluation & Quality Assurance
Preventing Silent Performance Degradation
Model performance doesn't just degrade; it can deteriorate silently while appearing to function normally. Continuous evaluation is your early warning system for quality issues.
Automated Evaluation Framework:
Golden Dataset Management:
Curated test sets representing core use cases
Regular dataset updates to reflect evolving requirements
Stratified sampling across user segments and edge cases
Version-controlled truth labels with change tracking
Multi-Dimensional Evaluation: Assess performance across multiple dimensions:
Accuracy using task-specific metrics
Consistency across similar inputs
Robustness against adversarial examples
Fairness across demographic groups
Real-Time Quality Monitoring:
User feedback loops are integrated into the application
Implicit feedback from user behavior patterns
Expert review for high-stakes decisions
Automated quality scoring using auxiliary models
Performance Attribution: When quality drops, quickly identify the cause:
Model drift due to changing data patterns
Infrastructure issues affecting inference quality
Prompt degradation due to model updates
Data quality problems in upstream systems
Continuous Learning Pipeline:
Active learning to identify examples for human labeling
Model retraining triggers based on performance thresholds
A/B testing for model updates and improvements
Rollback procedures for failed deployments
Phase 8: Security & Compliance Framework
Protecting Against AI-Specific Threats
LLM security isn't traditional application security. These systems face unique threats like prompt injection, data extraction, and model inversion attacks. Your security framework must address both technical vulnerabilities and regulatory requirements.
Input Security:
Prompt Injection Prevention:
Input sanitization to remove potential injection attempts
Content filtering for malicious instructions
Context isolation between different user sessions
Privilege escalation detection and prevention
Data Protection:
PII detection and redaction in inputs and outputs
Sensitive information filtering using pattern matching
Access controls based on user roles and data sensitivity
Encryption for data in transit and at rest
Output Security:
Content Policy Enforcement:
Harmful content detection and blocking
Bias monitoring and mitigation strategies
Factual accuracy checks for high-stakes applications
Copyright protection is used to prevent the reproduction of protected content
Information Leakage Prevention:
Model inversion attack detection
Training data extraction monitoring
Adversarial prompt identification
Output similarity analysis to prevent data reconstruction
Compliance Framework:
GDPR compliance for EU users
CCPA compliance for California residents
Industry-specific regulations (HIPAA, SOX, etc.)
Audit trails for all system interactions
Incident Response:
Security incident response procedures
Breach notification protocols
Forensic analysis capabilities for security events
Recovery procedures for compromised systems
Phase 9: Cost Optimization & Financial Management
Preventing Runaway AI Expenses
LLM costs can spiral from hundreds to hundreds of thousands of dollars overnight. Effective cost management isn't just about saving money, it's about making AI economically sustainable for your business.
Cost Optimization Strategies:
Intelligent Caching:
Response caching for frequently asked questions
Semantic caching using embedding similarity
Partial computation caching for multi-step processes
Time-based cache invalidation for dynamic content
Model Tiering: Design a hierarchy of models for different complexity levels:
Simple queries → lightweight models (faster, cheaper)
Medium complexity → mid-tier models (balanced cost/performance)
Complex reasoning → premium models (highest accuracy)
Routing logic to automatically select the appropriate tier
Request Optimization:
Batch processing for non-real-time use cases
Request deduplication to avoid redundant processing
Context compression to reduce token usage
Smart truncation strategies for long inputs
Usage Monitoring & Controls:
Real-time cost tracking by user, feature, and use case
Budget alerts with automatic throttling options
Usage quotas to prevent abuse
Cost attribution for accurate department/project billing
Financial Planning:
Capacity planning based on growth projections
Reserved instance strategies for predictable workloads
Spot instance usage for batch processing
Multi-vendor strategies to optimize pricing
Phase 10: Disaster Recovery & Business Continuity
When Everything Goes Wrong
Disaster recovery for LLM systems involves unique challenges. Models can fail, APIs can go down, and costs can explode. Your disaster recovery plan must address both technical failures and business continuity.
Failure Scenarios & Responses:
Model Failure Patterns:
Primary model unavailable → Automatic failover to backup model
Quality degradation → Gradual rollback to the previous version
Cost spike → Emergency throttling and model downgrading
Security breach → Immediate isolation and forensic analysis
Business Continuity Strategy:
Graceful degradation to simpler functionality
User communication about temporary limitations
Priority user access during outages
Manual override procedures for critical operations
Multi-Region Deployment:
Active-passive setup with automatic failover
Data synchronization across regions
Latency optimization for global users
Compliance considerations for data locality
Recovery Procedures:
Automated health checks with recovery triggers
Rollback procedures for failed deployments
Data restoration from backup systems
Communication protocols for stakeholder updates
Testing & Validation:
Chaos engineering to test failure scenarios
Recovery time objectives and measurement
Regular DR drills with documented procedures
Post-incident analysis and improvement processes
Want to become an AWS Certified AI Practitioner?
The #1 mistake I see: reading whitepapers but not testing recall.
That is why I put together these practice tests that aren’t just exam prep; they help you:
• Identify weak spots
• Build exam confidence
• Learn why answers are correct/wrong with explanations + AWS doc links
👉 Even if you’re not ready to take the exam yet, taking the tests now will show you exactly where to focus.
🔗 Take a look - access anytime on desktop/mobile
Final Thoughts
The companies that succeed with LLMs won't be those with the biggest models or the most data. They'll be the organizations with the most robust operations.
Every phase in this lifecycle serves a critical purpose. Skip model validation, and you'll build on a shaky foundation. Ignore monitoring, and you'll fly blind into production disasters. Neglect security, and you'll face regulatory nightmares.
But implement this systematically, and you'll join the 27% of LLM deployments that not only reach production but thrive there.
What's your next step?
Pick the phase where your current system is weakest, and start there. Minor improvements compound quickly in LLM systems.
That’s it for today!
Did you enjoy this newsletter issue?
Share with your friends, colleagues, and your favorite social media platform.
Until next week — Amrut
Get in touch
You can find me on LinkedIn or X.
If you would like to request a topic to read, please feel free to contact me directly via LinkedIn or X.